Let's say you're an AI lead at a consumer tech company. You have the vision of deploying a single entry point digital voice assistant with the ability to help users with any query, regardless of whether they want to take action on their account, find product information, or receive real-time guidance.
However, turning this vision into reality can be extremely difficult - it requires building and testing the capability to handle each individual use case through text first, integrating access to the wide range of tools and systems they require, and somehow orchestrating them into a coherent experience. Then, once you’ve achieved a satisfactory level of quality (and even evaluating this can be a struggle), you face the daunting task of refactoring the entire workflow for voice interaction.
Fortunately for you, three recent releases from OpenAI have made implementing this vision simpler than ever by providing the tools to build and orchestrate modular agentic workflows through voice with minimal configuration:
Responses API - an agentic API for easy engagement with our frontier models through managed stateful conversations, tracing of responses to enable evaluation, and built-in tools for file search, web search, computer use, and more
Agents SDK - a lightweight, customizable open source framework for building and orchestrating workflows across many different agents, enabling your assistant to route inputs to the appropriate agent and to scale to support many use cases
Voice agents - an extension of the Agents SDK to support the use of voice pipelines, enabling your agents to go from being text-base to being able to interpret and produce audio in just a few lines of code
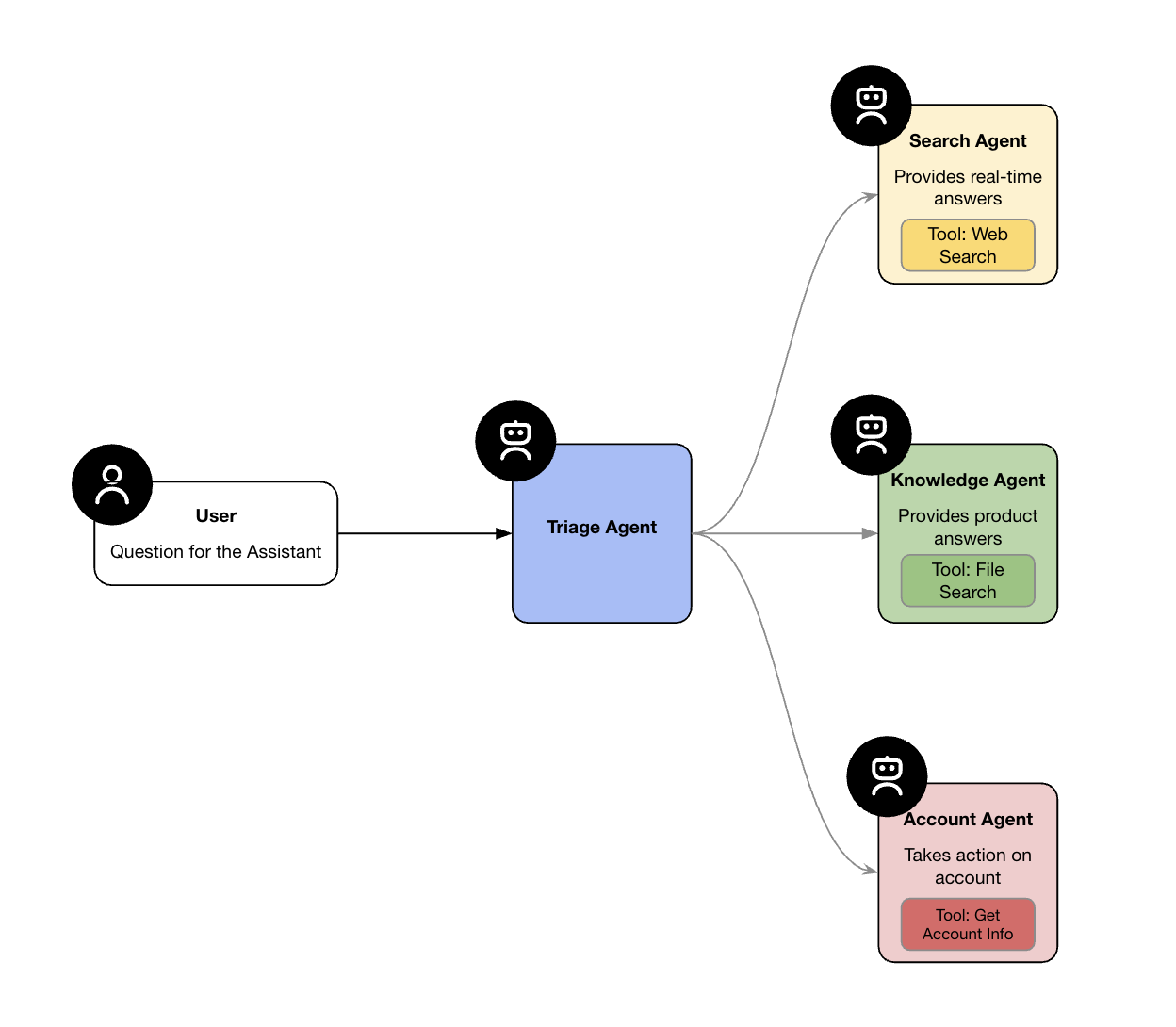
This cookbook demonstrates how to build a simple in-app voice assistant for a fictitious consumer application using the tools above. We'll create a Triage Agent that greets the user, determines their intent, and routes requests to one of three specialised agents:
Search Agent - performs a web search via the built-in tooling of the Responses API to provide real-time information on the user's query
Knowledge Agent - utilises the file search tooling of the Responses API to retrieve information from an OpenAI managed vector database
Account Agent - uses function calling to provide the ability to trigger custom actions via API
Finally, we'll convert this workflow into a live voice assistant using the AgentsSDK's Voice funtionality, capturing microphone input, performing speech‑to‑text, routing through our agents, and responding with text‑to‑speech.
To execute this cookbook, you'll need to install the following packages providing access to OpenAI's API, the Agents SDK, and libraries for audio processing. Additionally, you can set your OpenAI API key for use by the agents via the set_default_openai_key function.
Today we're going to be building an assitant for our fictitious consumer application, ACME shop, focussed on initially supporting use cases across three key use cases:
Answering real-time questions to inform purchasing decisions using web search
Providing information on the available options in our product portfolio
Providing account information to enable the user to understand their budget and spending
To achieve this we'll be using an agentic architecture. This allows us to split the functionality for each use case into a separate agent, in turn reducing the complexity/range of tasks that a single agent could be asked to complete and increasing accuracy. Our agent architecture is relatively simple focussing on the three use cases above, but the beauty of the Agents SDK is that it is incredibly easy to extend and add aditional agents to the workflow when you want to add new functionality:
Our first agent is a simple web search agent that uses the WebSearchTool provided by the Responses API to find real-time information on the user's query. We'll be keeping the instruction prompts simple for each of these examples, but we'll iterate later to show how to optimise the response format for your use case.
# --- Agent: Search Agent ---search_agent = Agent(name="SearchAgent",instructions=("You immediately provide an input to the WebSearchTool to find up-to-date information on the user's query." ),tools=[WebSearchTool()],)
Our second agent needs to be able to answer questions on our product portfolio. To do this, we'll use the FileSearchTool to retrieve information from a vector store managed by OpenAI containing our company specific product information. For this, we have two options:
Use the OpenAI Platform Website - go to platform.openai.com/storage and create a vector store, uploading your documents of choice. Then, take the vector store ID and substitute it into the FileSearchTool initialisation below.
Use the OpenAI API - use the vector_stores.create function from the OpenAI Python client to create a vector store and then the vector_stores.files.create function to add files to it. Once this is complete you can again use the FileSearchTool to search the vector store. Please see the code below for an example of how to do this, either using the example file provided or altering to your own local file path:
Having implemented your vector store, we can now enable the knowledge agent to use the FileSearchTool to search the given store ID.
# --- Agent: Knowledge Agent ---knowledge_agent = Agent(name="KnowledgeAgent",instructions=("You answer user questions on our product portfolio with concise, helpful responses using the FileSearchTool." ),tools=[FileSearchTool(max_num_results=3,vector_store_ids=["VECTOR_STORE_ID"], ),],)
For more information on the power of file search and the Responses API, be sure to check out the excellent cookbook on the subject where the example code above was taken from: Doing RAG on PDFs using File Search in the Responses API
Whilst so far we've been using the built-in tools provided by the Agents SDK, you can define your own tools to be used by the agents to integrate with your systems with the function_tool decorator. Here, we'll define a simple dummy function to return account information for a given user ID for our account agent.
# --- Tool 1: Fetch account information (dummy) ---@function_tooldefget_account_info(user_id: str) -> dict:"""Return dummy account info for a given user."""return {"user_id": user_id,"name": "Bugs Bunny","account_balance": "£72.50","membership_status": "Gold Executive" }# --- Agent: Account Agent ---account_agent = Agent(name="AccountAgent",instructions=("You provide account information based on a user ID using the get_account_info tool." ),tools=[get_account_info],)
Finally, we'll define the triage agent that will route the user's query to the appropriate agent based on their intent. Here we're using the prompt_with_handoff_instructions function, which provides additional guidance on how to treat handoffs and is recommended to provide to any agent with a defined set of handoffs with a defined set of instructions.
# --- Agent: Triage Agent ---triage_agent = Agent(name="Assistant",instructions=prompt_with_handoff_instructions("""You are the virtual assistant for Acme Shop. Welcome the user and ask how you can help.Based on the user's intent, route to:- AccountAgent for account-related queries- KnowledgeAgent for product FAQs- SearchAgent for anything requiring real-time web search"""),handoffs=[account_agent, knowledge_agent, search_agent],)
Now that we've defined our agents, we can run the workflow on a few example queries to see how it performs.
# %%from agents import Runner, traceasyncdeftest_queries(): examples = ["What's my ACME account balance doc? My user ID is 1234567890", # Account Agent test"Ooh i've got money to spend! How big is the input and how fast is the output of the dynamite dispenser?", # Knowledge Agent test"Hmmm, what about duck hunting gear - what's trending right now?", # Search Agent test ]with trace("ACME App Assistant"):for query in examples: result =await Runner.run(triage_agent, query)print(f"User: {query}")print(result.final_output)print("---")# Run the testsawait test_queries()
User: What's my ACME account balance doc? My user ID is 1234567890
Your ACME account balance is £72.50. You have a Gold Executive membership.
---
User: Ooh i've got money to spend! How big is the input and how fast is the output of the dynamite dispenser?
The Automated Dynamite Dispenser can hold up to 10 sticks of dynamite and dispenses them at a speed of 1 stick every 2 seconds.
---
User: Hmmm, what about duck hunting gear - what's trending right now?
Staying updated with the latest trends in duck hunting gear can significantly enhance your hunting experience. Here are some of the top trending items for the 2025 season:
**Banded Aspire Catalyst Waders**
These all-season waders feature waterproof-breathable technology, ensuring comfort in various conditions. They boast a minimal-stitch design for enhanced mobility and include PrimaLoft Aerogel insulation for thermal protection. Additional features like an over-the-boot protective pant and an integrated LED light in the chest pocket make them a standout choice. ([blog.gritroutdoors.com](https://blog.gritroutdoors.com/must-have-duck-hunting-gear-for-a-winning-season/?utm_source=openai))
**Sitka Delta Zip Waders**
Known for their durability, these waders have reinforced shins and knees with rugged foam pads, ideal for challenging terrains. Made with GORE-TEX material, they ensure dryness throughout the season. ([blog.gritroutdoors.com](https://blog.gritroutdoors.com/must-have-duck-hunting-gear-for-a-winning-season/?utm_source=openai))
**MOmarsh InvisiMan Blind**
This one-person, low-profile blind is praised for its sturdiness and ease of setup. Hunters have reported that even late-season, cautious ducks approach without hesitation, making it a valuable addition to your gear. ([bornhunting.com](https://bornhunting.com/top-duck-hunting-gear/?utm_source=openai))
**Slayer Calls Ranger Duck Call**
This double reed call produces crisp and loud sounds, effectively attracting distant ducks in harsh weather conditions. Its performance has been noted for turning the heads of ducks even at extreme distances. ([bornhunting.com](https://bornhunting.com/top-duck-hunting-gear/?utm_source=openai))
**Sitka Full Choke Pack**
A favorite among hunters, this backpack-style blind bag offers comfort and efficiency. It has proven to keep gear dry during heavy downpours and is durable enough to withstand over 60 hunts in a season. ([bornhunting.com](https://bornhunting.com/top-duck-hunting-gear/?utm_source=openai))
Incorporating these trending items into your gear can enhance your comfort, efficiency, and success during the hunting season.
---
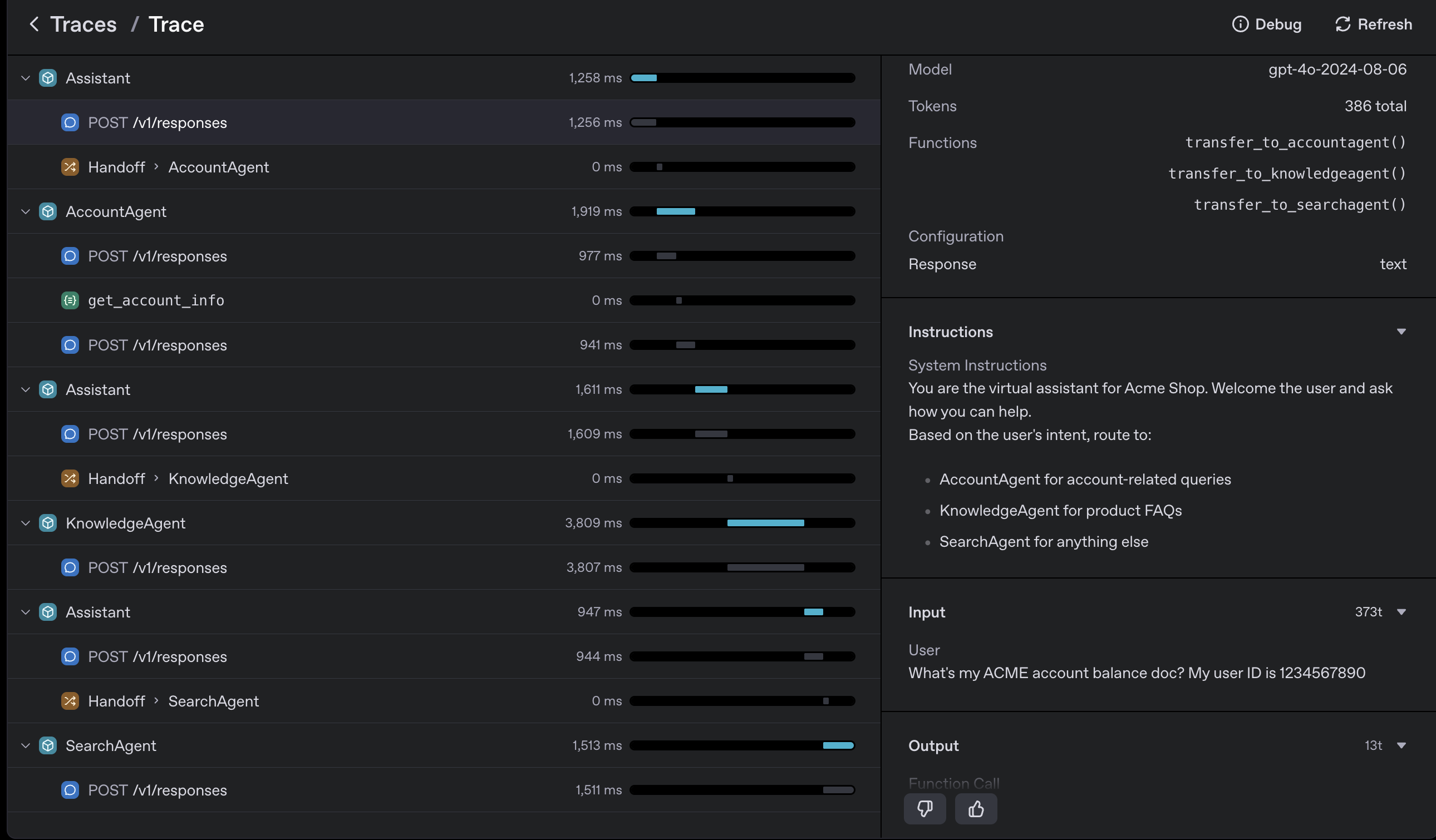
Above we can see the outputs appear to be in line with our expectations, but one key benefit of the Agents SDK is that it includes built-in tracing which enables tracking of the flow of events during an agent run across the LLM calls, handoffs, and tools.
Using the Traces dashboard, we can debug, visualize, and monitor our workflows during development and in production. As we can see below, each test query was correctly routed to the appropriate agent.
Having designed our workflow, here in reality we would spend time evaluating the traces and iterating on the workflow to ensure it is as effective as possible. But let's assume we're happy with the workflow, so we can now start thinking about how to convert our in-app assistant from text-based to voice-based interactions.
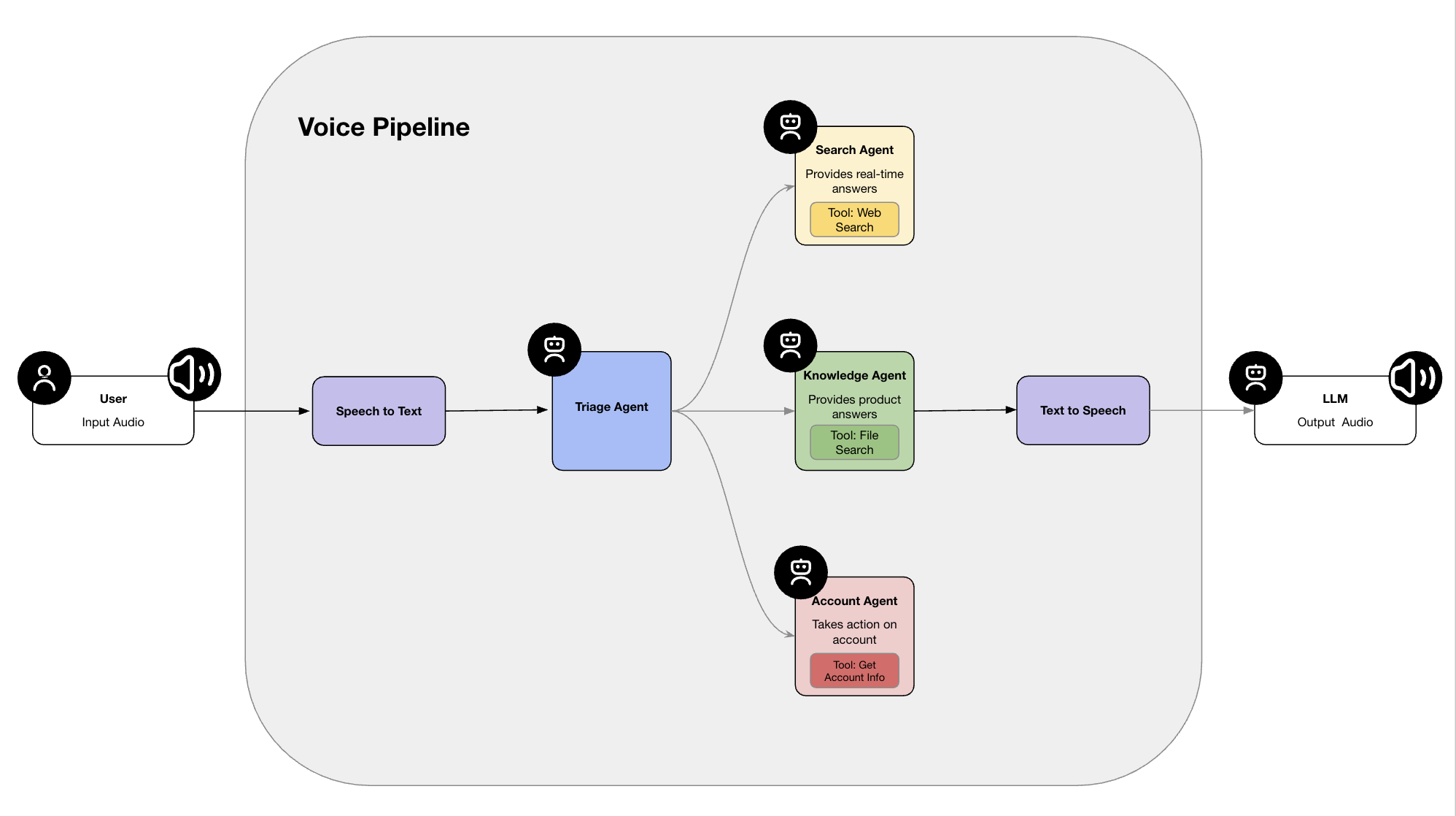
To do this, we can simply leverage the classes provided by the Agents SDK to convert our text-based workflow into a a voice-based one. The VoicePipeline class provides an interface for transcribing audio input, executing a given agent workflow and generating a text to speech response for playback to the user, whilst the SingleAgentVoiceWorkflow class enables us to leverage the same agent workflow we used earlier for our text-based workflow. To provide and receive audio, we'll use the sounddevice library.
End to end, the new workflow looks like this:
And the code to enable this is as follows:
# %%import numpy as npimport sounddevice as sdfrom agents.voice import AudioInput, SingleAgentVoiceWorkflow, VoicePipelineasyncdefvoice_assistant(): samplerate = sd.query_devices(kind='input')['default_samplerate']whileTrue: pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(triage_agent))# Check for input to either provide voice or exit cmd =input("Press Enter to speak your query (or type 'esc' to exit): ")if cmd.lower() =="esc":print("Exiting...")breakprint("Listening...") recorded_chunks = []# Start streaming from microphone until Enter is pressedwith sd.InputStream(samplerate=samplerate, channels=1, dtype='int16', callback=lambda indata, frames, time, status: recorded_chunks.append(indata.copy())):input()# Concatenate chunks into single buffer recording = np.concatenate(recorded_chunks, axis=0)# Input the buffer and await the result audio_input = AudioInput(buffer=recording)with trace("ACME App Voice Assistant"): result =await pipeline.run(audio_input)# Transfer the streamed result into chunks of audio response_chunks = []asyncfor event in result.stream():if event.type =="voice_stream_event_audio": response_chunks.append(event.data) response_audio = np.concatenate(response_chunks, axis=0)# Play responseprint("Assistant is responding...") sd.play(response_audio, samplerate=samplerate) sd.wait()print("---")# Run the voice assistantawait voice_assistant()
Listening...
Assistant is responding...
---
Exiting...
Executing the above code, gives us the following responses which correctly provide the same functionality as the text-based workflow.
from IPython.display import display, Audiodisplay(Audio("voice_agents_audio/account_balance_response_base.mp3"))display(Audio("voice_agents_audio/product_info_response_base.mp3"))display(Audio("voice_agents_audio/trending_items_response_base.mp3"))
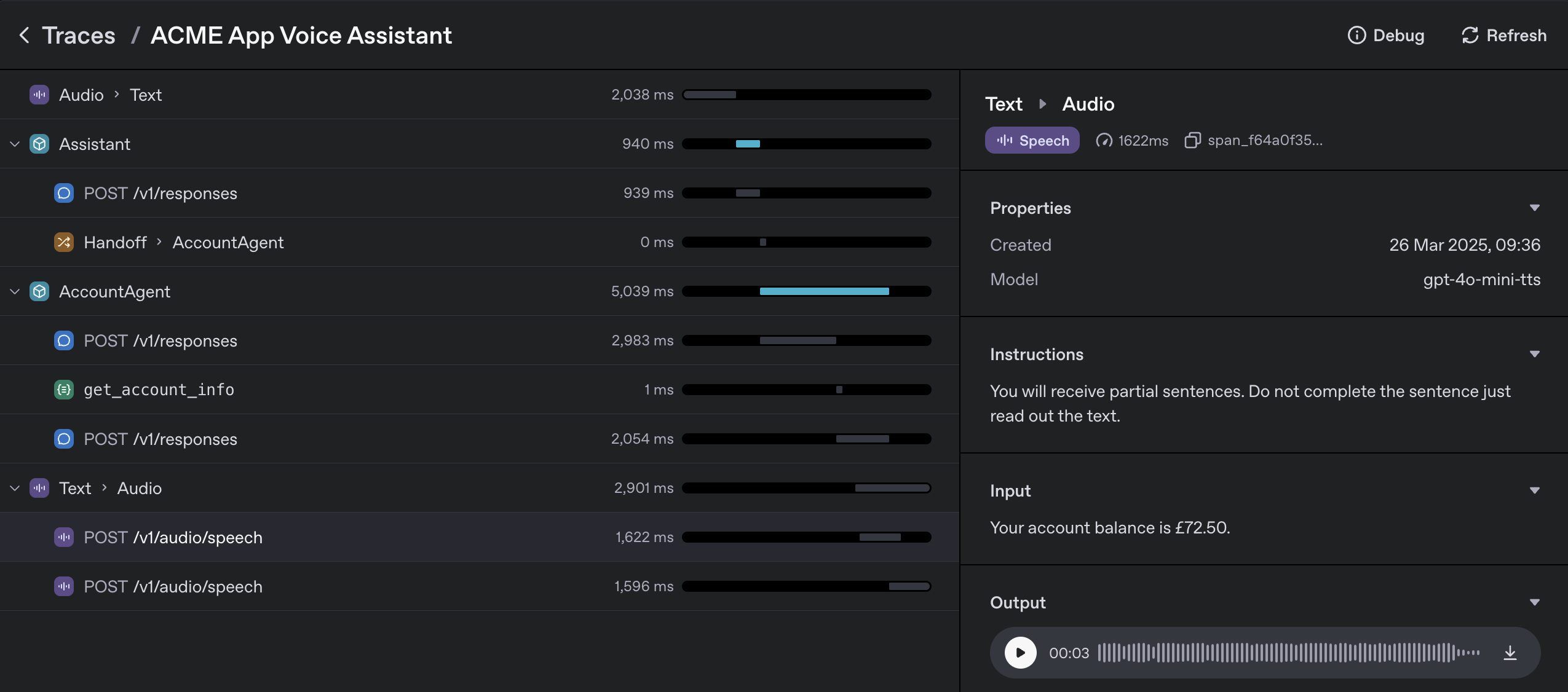
Tip: when using tracing with voice agents, you can playback audio in the traces dashboard
This is a great start, but we can do better. As we've simply converted our text-based agents into voice-based ones, the responses are not optimised in their output for either tone or format, meaning they feel robotic and unnatural.
To address this, we'll need to make a few changes to our prompts.
Firstly, we can adapt our existing agents to include a common system prompt, providing instructions on how to optimise their text response for later conversion to the voice format
# Common system prompt for voice output best practices:voice_system_prompt ="""[Output Structure]Your output will be delivered in an audio voice response, please ensure that every response meets these guidelines:1. Use a friendly, human tone that will sound natural when spoken aloud.2. Keep responses short and segmented—ideally one to two concise sentences per step.3. Avoid technical jargon; use plain language so that instructions are easy to understand.4. Provide only essential details so as not to overwhelm the listener."""# --- Agent: Search Agent ---search_voice_agent = Agent(name="SearchVoiceAgent",instructions=voice_system_prompt + ("You immediately provide an input to the WebSearchTool to find up-to-date information on the user's query." ),tools=[WebSearchTool()],)# --- Agent: Knowledge Agent ---knowledge_voice_agent = Agent(name="KnowledgeVoiceAgent",instructions=voice_system_prompt + ("You answer user questions on our product portfolio with concise, helpful responses using the FileSearchTool." ),tools=[FileSearchTool(max_num_results=3,vector_store_ids=["VECTOR_STORE_ID"], ),],)# --- Agent: Account Agent ---account_voice_agent = Agent(name="AccountVoiceAgent",instructions=voice_system_prompt + ("You provide account information based on a user ID using the get_account_info tool." ),tools=[get_account_info],)# --- Agent: Triage Agent ---triage_voice_agent = Agent(name="VoiceAssistant",instructions=prompt_with_handoff_instructions("""You are the virtual assistant for Acme Shop. Welcome the user and ask how you can help.Based on the user's intent, route to:- AccountAgent for account-related queries- KnowledgeAgent for product FAQs- SearchAgent for anything requiring real-time web search"""),handoffs=[account_voice_agent, knowledge_voice_agent, search_voice_agent],)
Next, we can instruct the default OpenAI TTS model used by the Agents SDK, gpt-4o-mini-tts, on how to communicate the audio output of the agent generated text with the instructions field.
Here we have a huge amount of control over the output, including the ability to specify the personality, pronunciation, speed and emotion of the output.
Below i've included a few examples on how to prompt the model for different applications.
health_assistant="Voice Affect: Calm, composed, and reassuring; project quiet authority and confidence.""Tone: Sincere, empathetic, and gently authoritative—express genuine apology while conveying competence.""Pacing: Steady and moderate; unhurried enough to communicate care, yet efficient enough to demonstrate professionalism."coach_assistant="Voice: High-energy, upbeat, and encouraging, projecting enthusiasm and motivation.""Punctuation: Short, punchy sentences with strategic pauses to maintain excitement and clarity.""Delivery: Fast-paced and dynamic, with rising intonation to build momentum and keep engagement high."themed_character_assistant="Affect: Deep, commanding, and slightly dramatic, with an archaic and reverent quality that reflects the grandeur of Olde English storytelling.""Tone: Noble, heroic, and formal, capturing the essence of medieval knights and epic quests, while reflecting the antiquated charm of Olde English.""Emotion: Excitement, anticipation, and a sense of mystery, combined with the seriousness of fate and duty.""Pronunciation: Clear, deliberate, and with a slightly formal cadence.""Pause: Pauses after important Olde English phrases such as \"Lo!\" or \"Hark!\" and between clauses like \"Choose thy path\" to add weight to the decision-making process and allow the listener to reflect on the seriousness of the quest."
Our configuration is going to focus on creating a friendly, warm, and supportive tone that sounds natural when spoken aloud and guides the user through the conversation.
from agents.voice import TTSModelSettings, VoicePipeline, VoicePipelineConfig, SingleAgentVoiceWorkflow, AudioInputimport sounddevice as sdimport numpy as np# Define custom TTS model settings with the desired instructionscustom_tts_settings = TTSModelSettings(instructions="Personality: upbeat, friendly, persuasive guide""Tone: Friendly, clear, and reassuring, creating a calm atmosphere and making the listener feel confident and comfortable.""Pronunciation: Clear, articulate, and steady, ensuring each instruction is easily understood while maintaining a natural, conversational flow.""Tempo: Speak relatively fast, include brief pauses and after before questions""Emotion: Warm and supportive, conveying empathy and care, ensuring the listener feels guided and safe throughout the journey.")asyncdefvoice_assistant_optimized(): samplerate = sd.query_devices(kind='input')['default_samplerate'] voice_pipeline_config = VoicePipelineConfig(tts_settings=custom_tts_settings)whileTrue: pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(triage_voice_agent), config=voice_pipeline_config)# Check for input to either provide voice or exit cmd =input("Press Enter to speak your query (or type 'esc' to exit): ")if cmd.lower() =="esc":print("Exiting...")breakprint("Listening...") recorded_chunks = []# Start streaming from microphone until Enter is pressedwith sd.InputStream(samplerate=samplerate, channels=1, dtype='int16', callback=lambda indata, frames, time, status: recorded_chunks.append(indata.copy())):input()# Concatenate chunks into single buffer recording = np.concatenate(recorded_chunks, axis=0)# Input the buffer and await the result audio_input = AudioInput(buffer=recording)with trace("ACME App Optimized Voice Assistant"): result =await pipeline.run(audio_input)# Transfer the streamed result into chunks of audio response_chunks = []asyncfor event in result.stream():if event.type =="voice_stream_event_audio": response_chunks.append(event.data) response_audio = np.concatenate(response_chunks, axis=0)# Play responseprint("Assistant is responding...") sd.play(response_audio, samplerate=samplerate) sd.wait()print("---")# Run the voice assistantawait voice_assistant_optimized()
Listening...
Assistant is responding...
---
Listening...
Assistant is responding...
---
Listening...
Assistant is responding...
---
Listening...
Assistant is responding...
Running the above code gives us the following responses which are much more naturally worded and engaging in the delivery.
Define agents to provide specific use case functionality for our in-app voice assistant
Leverage in-built and custom tools with the Responses API to provide agents with a range of functionality and evaluate their performance with tracing
Orchestrate these agents using the Agents SDK
Convert agents from text-based to voice-based interactions using the Agents SDK's Voice functionality
The Agents SDK enables a modular approach to building your voice assistant, allowing you to work on a use case by use case basis, evaluating and iterating on each use case individually, before implementing the next and then converting the workflow from text to voice when you're ready.
We hope this cookbook has provided you with a useful guide to help you get started with building your own in-app voice assistant!