import asyncio
from collections import deque
from typing import Optional, List, Tuple, Dict, Any
Record = Dict[str, Dict[str, Any]] # {"msg": {...}, "meta": {...}}
class SummarizingSession:
"""
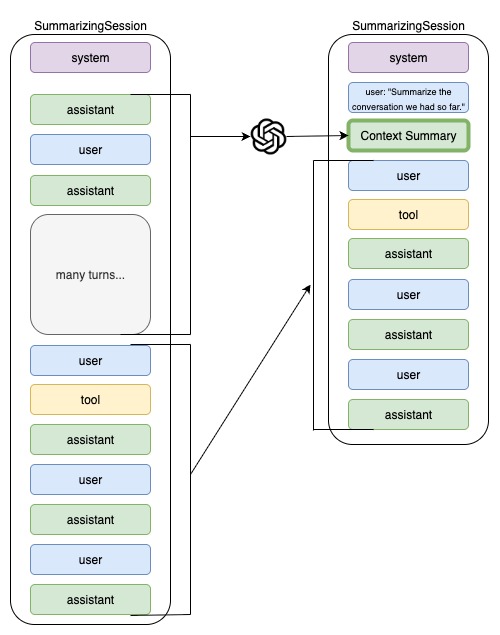
Session that keeps only the last N *user turns* verbatim and summarizes the rest.
- A *turn* starts at a real user message and includes everything until the next real user message.
- When the number of real user turns exceeds `context_limit`, everything before the earliest
of the last `keep_last_n_turns` user-turn starts is summarized into a synthetic user→assistant pair.
- Stores full records (message + metadata). Exposes:
• get_items(): model-safe messages only (no metadata)
• get_full_history(): [{"message": msg, "metadata": meta}, ...]
"""
# Only these keys are ever sent to the model; the rest live in metadata.
_ALLOWED_MSG_KEYS = {"role", "content", "name"}
def __init__(
self,
keep_last_n_turns: int = 3,
context_limit: int = 3,
summarizer: Optional["Summarizer"] = None,
session_id: Optional[str] = None,
):
assert context_limit >= 1
assert keep_last_n_turns >= 0
assert keep_last_n_turns <= context_limit, "keep_last_n_turns should not be greater than context_limit"
self.keep_last_n_turns = keep_last_n_turns
self.context_limit = context_limit
self.summarizer = summarizer
self.session_id = session_id or "default"
self._records: deque[Record] = deque()
self._lock = asyncio.Lock()
# --------- public API used by your runner ---------
async def get_items(self, limit: Optional[int] = None) -> List[Dict[str, Any]]:
"""Return model-safe messages only (no metadata)."""
async with self._lock:
data = list(self._records)
msgs = [self._sanitize_for_model(rec["msg"]) for rec in data]
return msgs[-limit:] if limit else msgs
async def add_items(self, items: List[Dict[str, Any]]) -> None:
"""Append new items and, if needed, summarize older turns."""
# 1) Ingest items
async with self._lock:
for it in items:
msg, meta = self._split_msg_and_meta(it)
self._records.append({"msg": msg, "meta": meta})
need_summary, boundary = self._summarize_decision_locked()
# 2) No summarization needed → just normalize flags and exit
if not need_summary:
async with self._lock:
self._normalize_synthetic_flags_locked()
return
# 3) Prepare summary prefix (model-safe copy) outside the lock
async with self._lock:
snapshot = list(self._records)
prefix_msgs = [r["msg"] for r in snapshot[:boundary]]
user_shadow, assistant_summary = await self._summarize(prefix_msgs)
# 4) Re-check and apply summary atomically
async with self._lock:
still_need, new_boundary = self._summarize_decision_locked()
if not still_need:
self._normalize_synthetic_flags_locked()
return
snapshot = list(self._records)
suffix = snapshot[new_boundary:] # keep-last-N turns live here
# Replace with: synthetic pair + suffix
self._records.clear()
self._records.extend([
{
"msg": {"role": "user", "content": user_shadow},
"meta": {
"synthetic": True,
"kind": "history_summary_prompt",
"summary_for_turns": f"< all before idx {new_boundary} >",
},
},
{
"msg": {"role": "assistant", "content": assistant_summary},
"meta": {
"synthetic": True,
"kind": "history_summary",
"summary_for_turns": f"< all before idx {new_boundary} >",
},
},
])
self._records.extend(suffix)
# Ensure all real user/assistant messages explicitly have synthetic=False
self._normalize_synthetic_flags_locked()
async def pop_item(self) -> Optional[Dict[str, Any]]:
"""Pop the latest message (model-safe), if any."""
async with self._lock:
if not self._records:
return None
rec = self._records.pop()
return dict(rec["msg"])
async def clear_session(self) -> None:
"""Remove all records."""
async with self._lock:
self._records.clear()
def set_max_turns(self, n: int) -> None:
"""
Back-compat shim for old callers: update `context_limit`
and clamp `keep_last_n_turns` if needed.
"""
assert n >= 1
self.context_limit = n
if self.keep_last_n_turns > self.context_limit:
self.keep_last_n_turns = self.context_limit
# Full history (debugging/analytics/observability)
async def get_full_history(self, limit: Optional[int] = None) -> List[Dict[str, Any]]:
"""
Return combined history entries in the shape:
{"message": {role, content[, name]}, "metadata": {...}}
This is NOT sent to the model; for logs/UI/debugging only.
"""
async with self._lock:
data = list(self._records)
out = [{"message": dict(rec["msg"]), "metadata": dict(rec["meta"])} for rec in data]
return out[-limit:] if limit else out
# Back-compat alias
async def get_items_with_metadata(self, limit: Optional[int] = None) -> List[Dict[str, Any]]:
return await self.get_full_history(limit)
# Internals
def _split_msg_and_meta(self, it: Dict[str, Any]) -> Tuple[Dict[str, Any], Dict[str, Any]]:
"""
Split input into (msg, meta):
- msg keeps only _ALLOWED_MSG_KEYS; if role/content missing, default them.
- everything else goes under meta (including nested "metadata" if provided).
- default synthetic=False for real user/assistant unless explicitly set.
"""
msg = {k: v for k, v in it.items() if k in self._ALLOWED_MSG_KEYS}
extra = {k: v for k, v in it.items() if k not in self._ALLOWED_MSG_KEYS}
meta = dict(extra.pop("metadata", {}))
meta.update(extra)
msg.setdefault("role", "user")
msg.setdefault("content", str(it))
role = msg.get("role")
if role in ("user", "assistant") and "synthetic" not in meta:
meta["synthetic"] = False
return msg, meta
@staticmethod
def _sanitize_for_model(msg: Dict[str, Any]) -> Dict[str, Any]:
"""Drop anything not allowed in model calls."""
return {k: v for k, v in msg.items() if k in SummarizingSession._ALLOWED_MSG_KEYS}
@staticmethod
def _is_real_user_turn_start(rec: Record) -> bool:
"""True if record starts a *real* user turn (role=='user' and not synthetic)."""
return (
rec["msg"].get("role") == "user"
and not rec["meta"].get("synthetic", False)
)
def _summarize_decision_locked(self) -> Tuple[bool, int]:
"""
Decide whether to summarize and compute the boundary index.
Returns:
(need_summary, boundary_idx)
If need_summary:
• boundary_idx is the earliest index among the last `keep_last_n_turns`
*real* user-turn starts.
• Everything before boundary_idx becomes the summary prefix.
"""
user_starts: List[int] = [
i for i, rec in enumerate(self._records) if self._is_real_user_turn_start(rec)
]
real_turns = len(user_starts)
# Not over the limit → nothing to do
if real_turns <= self.context_limit:
return False, -1
# Keep zero turns verbatim → summarize everything
if self.keep_last_n_turns == 0:
return True, len(self._records)
# Otherwise, keep the last N turns; summarize everything before the earliest of those
if len(user_starts) < self.keep_last_n_turns:
return False, -1 # defensive (shouldn't happen given the earlier check)
boundary = user_starts[-self.keep_last_n_turns]
# If there is nothing before boundary, there is nothing to summarize
if boundary <= 0:
return False, -1
return True, boundary
def _normalize_synthetic_flags_locked(self) -> None:
"""Ensure all real user/assistant records explicitly carry synthetic=False."""
for rec in self._records:
role = rec["msg"].get("role")
if role in ("user", "assistant") and "synthetic" not in rec["meta"]:
rec["meta"]["synthetic"] = False
async def _summarize(self, prefix_msgs: List[Dict[str, Any]]) -> Tuple[str, str]:
"""
Ask the configured summarizer to compress the given prefix.
Uses model-safe messages only. If no summarizer is configured,
returns a graceful fallback.
"""
if not self.summarizer:
return ("Summarize the conversation we had so far.", "Summary unavailable.")
clean_prefix = [self._sanitize_for_model(m) for m in prefix_msgs]
return await self.summarizer.summarize(clean_prefix)