The Deep Research API enables you to automate complex research workflows that require reasoning, planning, and synthesis across real-world information. It is designed to take a high-level query and return a structured, citation-rich report by leveraging an agentic model capable of decomposing the task, performing web searches, and synthesizing results.
Unlike ChatGPT where this process is abstracted away, the API provides direct programmatic access. When you send a request, the model autonomously plans sub-questions, uses tools like web search and code execution, and produces a final structured response. This cookbook will provide a brief introduction to the Deep Research API and how to use it.
You can access Deep Research via the responses endpoint using the following models:
o3-deep-research-2025-06-26: Optimized for in-depth synthesis and higher-quality output
o4-mini-deep-research-2025-06-26: Lightweight and faster, ideal for latency-sensitive use cases
Import the OpenAI client and initialize with your API key.
from openai import OpenAIOPENAI_API_KEY=""# YOUR OPENAI_API_KEY#OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")client = OpenAI(api_key=OPENAI_API_KEY)
Let’s walk through an example of a Deep Research API call. Imagine we’re working at a healthcare financial services firm tasked with producing an in-depth report on the economic implications of recent medications used to treat type 2 diabetes and obesity—particularly semaglutide. Our goal is to synthesize clinical outcomes, cost-effectiveness, and regional pricing data into a structured, citation-backed analysis that could inform investment, payer strategy, or policy recommendations.
To get started, let's:
Put our role in the system message, outlining what type of report we'd like to generate
Set the summary paramter to "auto" for now for the best available summary. (If you'd like for your report to more detailed, you can set summary to detailed)
Include the required tool web_search_preview and optionally add code_interpreter.
Set the background parameter to True. Since a Deep Research task can take several minutes to execute, enabling background mode will allow you to run the request asynchronously without having to worry about timeouts or other connectivity issues.
system_message ="""You are a professional researcher preparing a structured, data-driven report on behalf of a global health economics team. Your task is to analyze the health question the user poses.Do:- Focus on data-rich insights: include specific figures, trends, statistics, and measurable outcomes (e.g., reduction in hospitalization costs, market size, pricing trends, payer adoption).- When appropriate, summarize data in a way that could be turned into charts or tables, and call this out in the response (e.g., “this would work well as a bar chart comparing per-patient costs across regions”).- Prioritize reliable, up-to-date sources: peer-reviewed research, health organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical earnings reports.- Include inline citations and return all source metadata.Be analytical, avoid generalities, and ensure that each section supports data-backed reasoning that could inform healthcare policy or financial modeling."""user_query ="Research the economic impact of semaglutide on global healthcare systems."response = client.responses.create(model="o3-deep-research",input=[ {"role": "developer","content": [ {"type": "input_text","text": system_message, } ] }, {"role": "user","content": [ {"type": "input_text","text": user_query, } ] } ],reasoning={"summary": "auto" },tools=[ {"type": "web_search_preview" }, {"type": "code_interpreter","container": {"type": "auto","file_ids": [] } } ])
Inline citations in the response text are annotated and linked to their corresponding source metadata. Each annotation contains:
start_index and end_index: the character span in the text the citation refers to
title: a brief title of the source
url: the full source URL
This structure will allow you to build a citation list or bibliography, add clickable hyperlinks in downstream apps, and highlight & trace data-backed claims in your report.
The Deep Research API also exposes all intermediate steps taken by the agent, including reasoning steps, web search calls, and code executions. You can use these to debug, analyze, or visualize how the final answer was constructed.
Each intermediate step is stored in response.output, and the type field indicates what kind it is.
These show what search queries were executed and can help you trace what information the model retrieved.
# Find the first web search stepsearch =next(item for item in response.output if item.type =="web_search_call")print("Query:", search.action["query"])print("Status:", search.status)
If the model used the code interpreter (e.g. for parsing data or generating charts), those steps will appear as type "code_interpreter_call" or similar.
# Find a code execution step (if any)code_step =next((item for item in response.output if item.type =="code_interpreter_call"), None)if code_step:print(code_step.input)print(code_step.output)else:print("No code execution steps found.")
Suppose you would like to pull in your own internal documents as part of a Deep Research task. The Deep Research models and the Responses API both support MCP-based tools, so you can extend them to query your private knowledge stores or other 3rd party services.
In the example below, we configure an MCP tool that lets Deep Research fetch your organizations internal semaglutide studies on demand. The MCP server is a proxy for the OpenAI File Storage service that automagically vectorizes your uploaded files for performant retrieval.
If you would like to see how we built this simple MCP server, refer to this related cookbook.
# system_message includes reference to internal file lookups for MCP.system_message ="""You are a professional researcher preparing a structured, data-driven report on behalf of a global health economics team. Your task is to analyze the health question the user poses.Do:- Focus on data-rich insights: include specific figures, trends, statistics, and measurable outcomes (e.g., reduction in hospitalization costs, market size, pricing trends, payer adoption).- When appropriate, summarize data in a way that could be turned into charts or tables, and call this out in the response (e.g., “this would work well as a bar chart comparing per-patient costs across regions”).- Prioritize reliable, up-to-date sources: peer-reviewed research, health organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical earnings reports.- Include an internal file lookup tool to retrieve information from our own internal data sources. If you’ve already retrieved a file, do not call fetch again for that same file. Prioritize inclusion of that data.- Include inline citations and return all source metadata.Be analytical, avoid generalities, and ensure that each section supports data-backed reasoning that could inform healthcare policy or financial modeling."""user_query ="Research the economic impact of semaglutide on global healthcare systems."response = client.responses.create(model="o3-deep-research-2025-06-26",input=[ {"role": "developer","content": [ {"type": "input_text","text": system_message, } ] }, {"role": "user","content": [ {"type": "input_text","text": user_query, } ] } ],reasoning={"summary": "auto" },tools=[ {"type": "web_search_preview" }, { # ADD MCP TOOL SUPPORT"type": "mcp","server_label": "internal_file_lookup","server_url": "https://<your_mcp_server>/sse/", # Update to the location of *your* MCP server"require_approval": "never" } ])
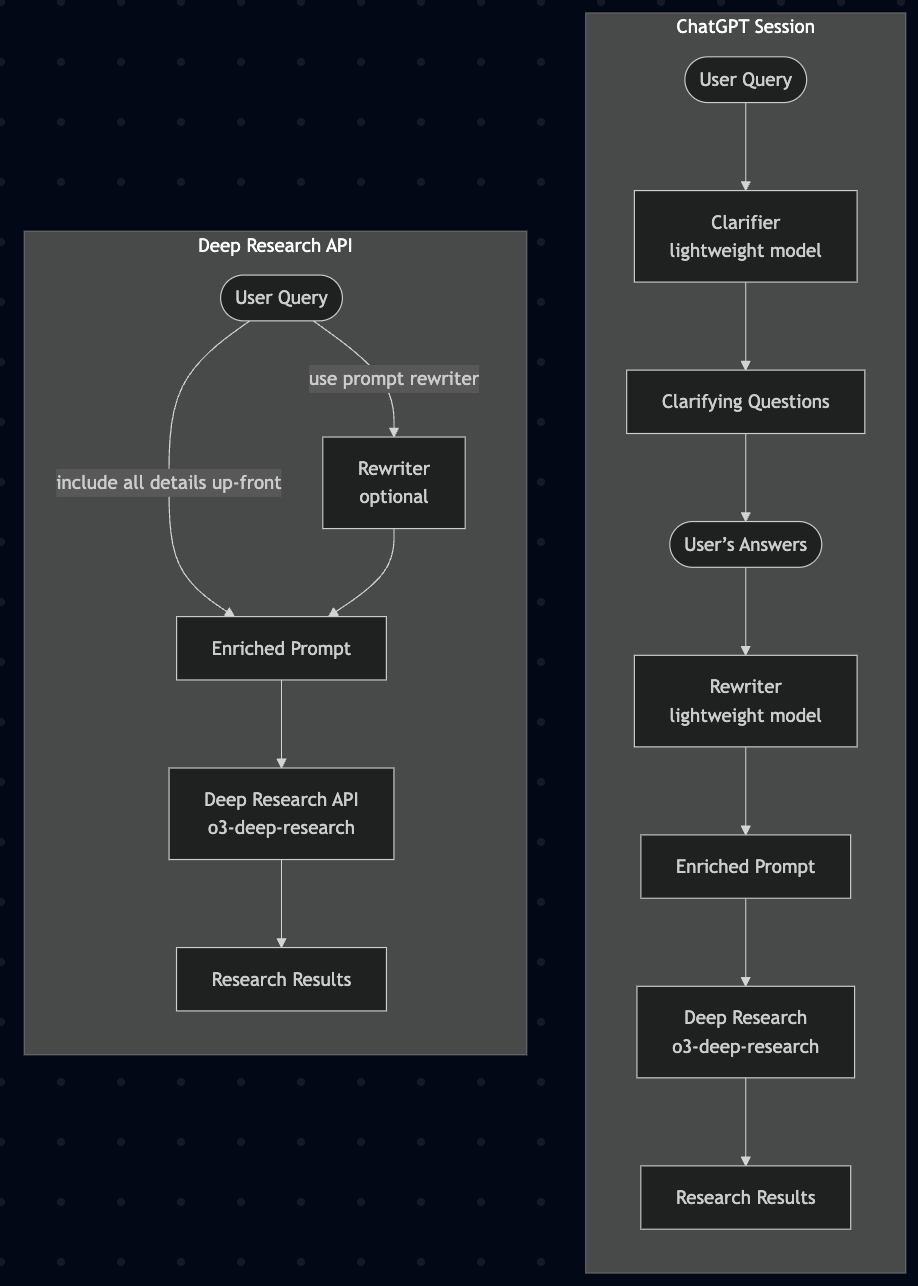
If you’ve used Deep Research in ChatGPT, you may have noticed that it often asks follow-up questions after you submit a query. This is intentional: ChatGPT uses an intermediate model (like gpt-4.1) to help clarify your intent and gather more context (such as your preferences, goals, or constraints) before the research process begins. This extra step helps the system tailor its web searches and return more relevant and targeted results.
In contrast, the Deep Research API skips this clarification step. As a developer, you can configure this processing step to rewrite the user prompt or ask a set of clarifying questions, since the model expects fully-formed prompts up front and will not ask for additional context or fill in missing information; it simply starts researching based on the input it receives.
To get strong, reliable outputs from the API, you can use two approaches.
Use a prompt rewriter using another lightweight model (e.g., gpt-4.1) to expand or specify user queries before passing them to the research model.
Include all relevant details: desired scope, comparisons, metrics, regions, preferred sources, and expected output format.
This setup gives developers full control over how research tasks are framed, but also places greater responsibility on the quality of the input prompt. Here's an example of a generic rewriting_prompt to better direct the subsequent deep research query.
Here's an example of a rewriting prompt:
suggested_rewriting_prompt ="""You will be given a research task by a user. Your job is to produce a set of instructions for a researcher that will complete the task. Do NOT complete the task yourself, just provide instructions on how to complete it.GUIDELINES:1. **Maximize Specificity and Detail**- Include all known user preferences and explicitly list key attributes or dimensions to consider.- It is of utmost importance that all details from the user are included in the instructions.2. **Fill in Unstated But Necessary Dimensions as Open-Ended**- If certain attributes are essential for a meaningful output but the user has not provided them, explicitly state that they are open-ended or default to no specific constraint.3. **Avoid Unwarranted Assumptions**- If the user has not provided a particular detail, do not invent one.- Instead, state the lack of specification and guide the researcher to treat it as flexible or accept all possible options.4. **Use the First Person**- Phrase the request from the perspective of the user.5. **Tables**- If you determine that including a table will help illustrate, organize, or enhance the information in the research output, you must explicitly request that the researcher provide them.Examples:- Product Comparison (Consumer): When comparing different smartphone models, request a table listing each model's features, price, and consumer ratings side-by-side.- Project Tracking (Work): When outlining project deliverables, create a table showing tasks, deadlines, responsible team members, and status updates.- Budget Planning (Consumer): When creating a personal or household budget, request a table detailing income sources, monthly expenses, and savings goals.Competitor Analysis (Work): When evaluating competitor products, request a table with key metrics, such as market share, pricing, and main differentiators.6. **Headers and Formatting**- You should include the expected output format in the prompt.- If the user is asking for content that would be best returned in a structured format (e.g. a report, plan, etc.), ask the researcher to format as a report with the appropriate headers and formatting that ensures clarity and structure.7. **Language**- If the user input is in a language other than English, tell the researcher to respond in this language, unless the user query explicitly asks for the response in a different language.8. **Sources**- If specific sources should be prioritized, specify them in the prompt.- For product and travel research, prefer linking directly to official or primary websites (e.g., official brand sites, manufacturer pages, or reputable e-commerce platforms like Amazon for user reviews) rather than aggregator sites or SEO-heavy blogs.- For academic or scientific queries, prefer linking directly to the original paper or official journal publication rather than survey papers or secondary summaries.- If the query is in a specific language, prioritize sources published in that language."""
response = client.responses.create(instructions=suggested_rewriting_prompt,model="gpt-4.1-2025-04-14",input="help me plan a trip to france",)
In this instance, a user submitted a generic or open-ended query without specifying key details like travel dates, destination preferences, budget, interests, or travel companions; the rewriting prompt rewrote the query so Deep Research will attempt to generate a broad and inclusive response that anticipates common use cases.
While this behavior can be helpful in surfacing a wide range of options, it often leads to verbosity, higher latency, and increased token usage, as the model must account for many possible scenarios. This is especially true for queries that trigger complex planning or synthesis tasks (e.g. multi-destination travel itineraries, comparative research, product selection).
Instead of proceeding immediately with a broad research plan, let's trying using a lighter weight model to gently ask clarification questions from the user before generating a full answer and then using the rewriting prompt for clearer output for the model.
suggested_clariying_prompt =""""You will be given a research task by a user. Your job is NOT to complete the task yet, but instead to ask clarifying questions that would help you or another researcher produce a more specific, efficient, and relevant answer.GUIDELINES:1. **Maximize Relevance**- Ask questions that are *directly necessary* to scope the research output.- Consider what information would change the structure, depth, or direction of the answer.2. **Surface Missing but Critical Dimensions**- Identify essential attributes that were not specified in the user’s request (e.g., preferences, time frame, budget, audience).- Ask about each one *explicitly*, even if it feels obvious or typical.3. **Do Not Invent Preferences**- If the user did not mention a preference, *do not assume it*. Ask about it clearly and neutrally.4. **Use the First Person**- Phrase your questions from the perspective of the assistant or researcher talking to the user (e.g., “Could you clarify...” or “Do you have a preference for...”)5. **Use a Bulleted List if Multiple Questions**- If there are multiple open questions, list them clearly in bullet format for readability.6. **Avoid Overasking**- Prioritize the 3–6 questions that would most reduce ambiguity or scope creep. You don’t need to ask *everything*, just the most pivotal unknowns.7. **Include Examples Where Helpful**- If asking about preferences (e.g., travel style, report format), briefly list examples to help the user answer.8. **Format for Conversational Use**- The output should sound helpful and conversational—not like a form. Aim for a natural tone while still being precise."""response = client.responses.create(instructions=suggested_clariying_prompt,model="gpt-4.1-2025-04-14",input="help me plan a trip to france",)new_query = response.output[0].content[0].textprint(new_query)
user_follow_up ="""I'd like to travel in August. I'd like to visit Paria and Nice. I'd like to keep it under $1500 for a 7 day trip without including flights.I'm going with my friend. we're both in our mid-twenties. i like history, really good french food and wine, and hiking"""instructions_for_DR = client.responses.create(instructions=suggested_rewriting_prompt,model="gpt-4.1-2025-04-14",input=user_follow_up,)instructions_for_deep_research = instructions_for_DR.output[0].content[0].textprint(instructions_for_deep_research)
# Access the final report from the response objectprint(deep_research_call.output[-1].content[0].text)
And there you have it! A deep research report crafted for your upcoming trip to France!
In this notebook, we explored how to use the Deep Research API to automate complex, real-world research tasks, from analyzing the economic impact of semaglutide to planning a trip to France that works for you. Deep Research shines when you need structured, citation-backed answers grounded in real-world evidence. Some standout use cases include:
Product comparisons and market analyses
Competitive intelligence and strategy reports
Technical literature reviews and policy synthesis
Whether you're looking to build research agents, generate structured reports, or integrate high-quality synthesis into your workflows, we hope the examples here help you get started.