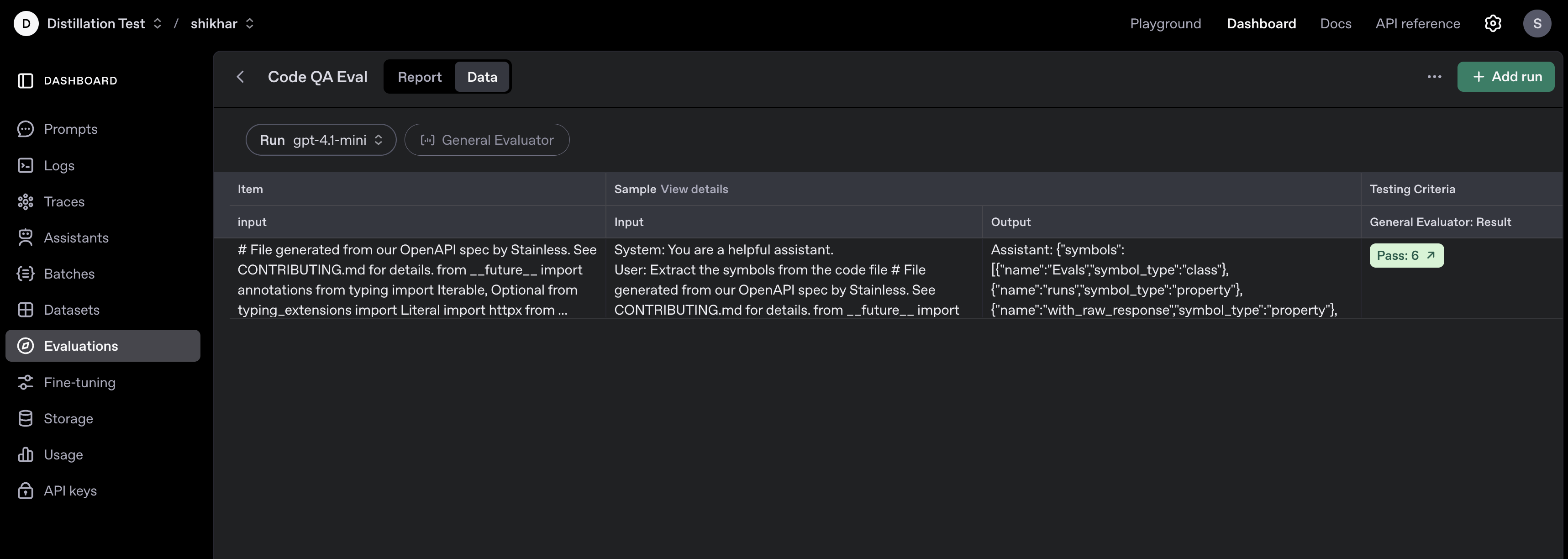
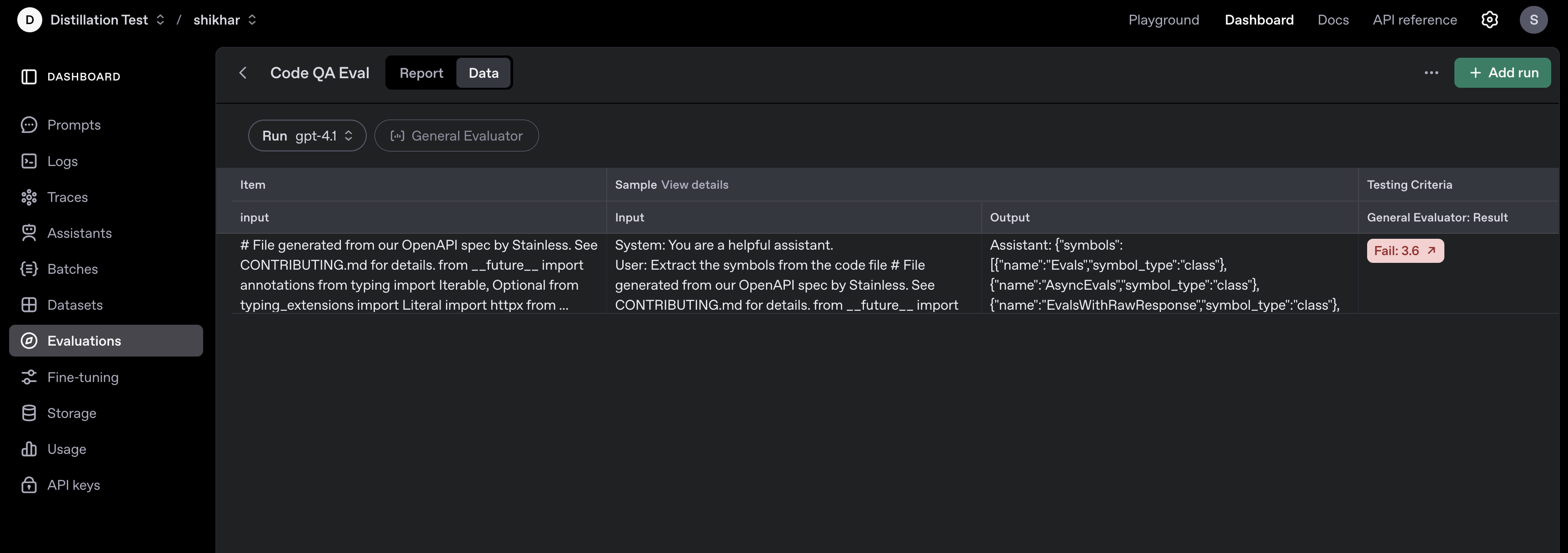
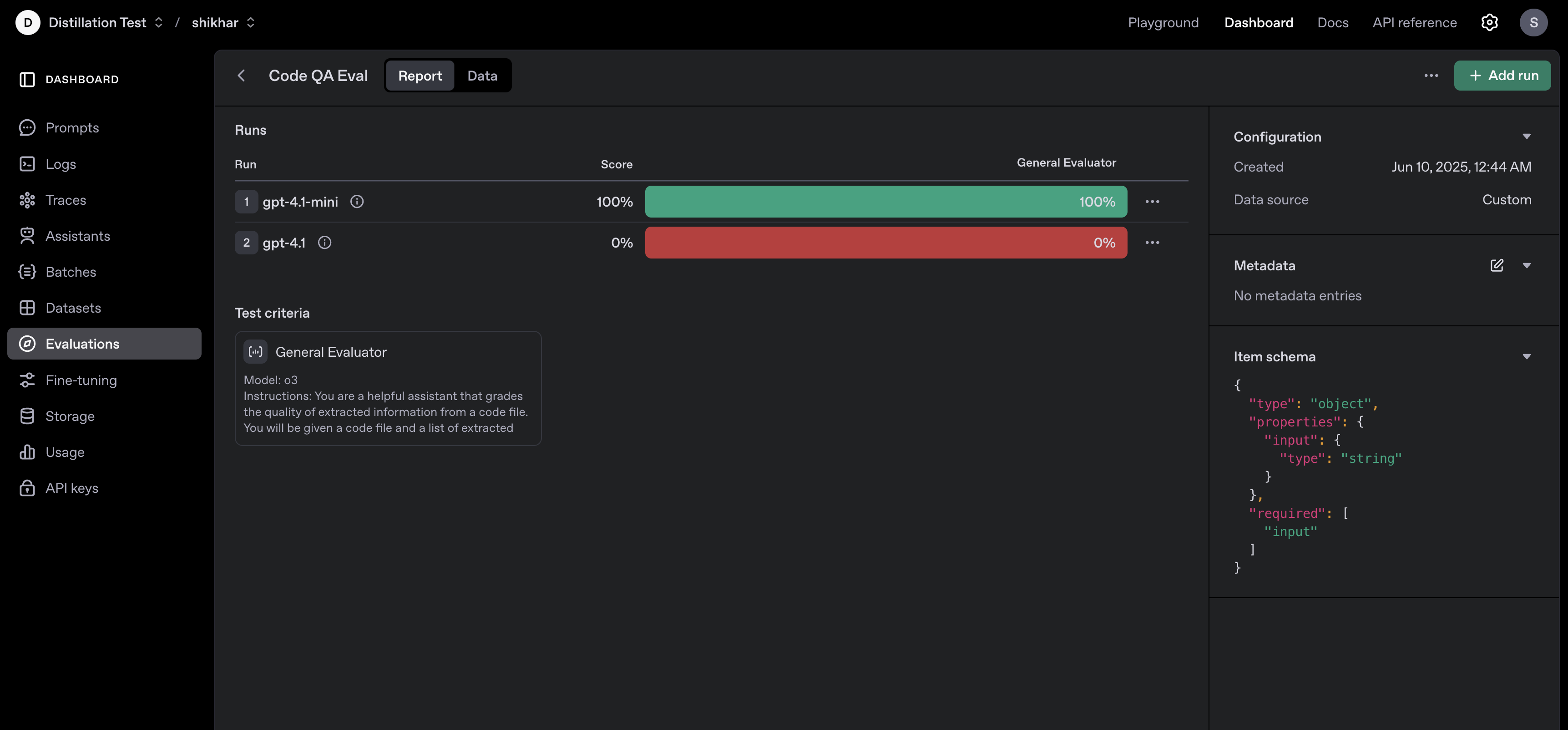
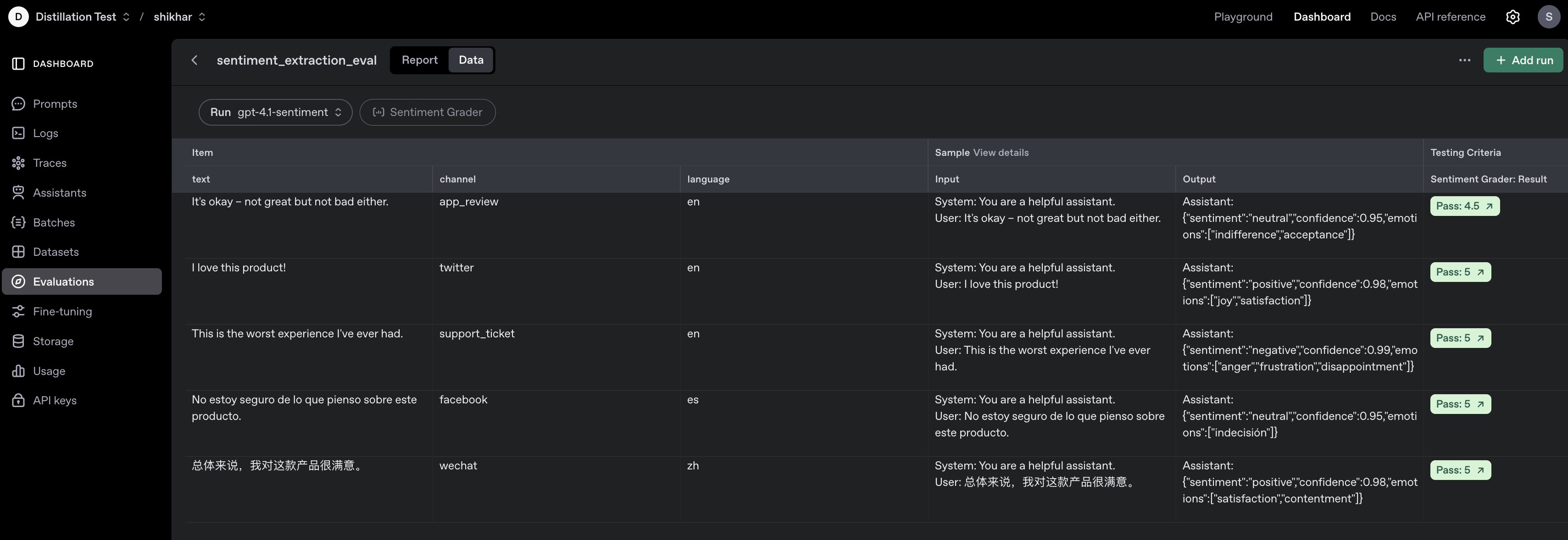
### Kick off model runs
gpt_4one_completions_run = client.evals.runs.create(
name="gpt-4.1",
eval_id=logs_eval.id,
data_source={
"type": "completions",
"source": {
"type": "file_content",
"content": [{"item": item} for item in get_dataset(limit=1)],
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "system",
"content": {"type": "input_text", "text": "You are a helpful assistant."},
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "Extract the symbols from the code file {{item.input}}",
},
},
],
},
"model": "gpt-4.1",
"sampling_params": {
"seed": 42,
"temperature": 0.7,
"max_completions_tokens": 10000,
"top_p": 0.9,
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "python_symbols",
"schema": {
"type": "object",
"properties": {
"symbols": {
"type": "array",
"description": "A list of symbols extracted from Python code.",
"items": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the symbol."},
"symbol_type": {
"type": "string", "description": "The type of the symbol, e.g., variable, function, class.",
},
},
"required": ["name", "symbol_type"],
"additionalProperties": False,
},
}
},
"required": ["symbols"],
"additionalProperties": False,
},
"strict": True,
},
},
},
},
)
gpt_4one_responses_run = client.evals.runs.create(
name="gpt-4.1-mini",
eval_id=logs_eval.id,
data_source={
"type": "responses",
"source": {
"type": "file_content",
"content": [{"item": item} for item in get_dataset(limit=1)],
},
"input_messages": {
"type": "template",
"template": [
{
"type": "message",
"role": "system",
"content": {"type": "input_text", "text": "You are a helpful assistant."},
},
{
"type": "message",
"role": "user",
"content": {
"type": "input_text",
"text": "Extract the symbols from the code file {{item.input}}",
},
},
],
},
"model": "gpt-4.1-mini",
"sampling_params": {
"seed": 42,
"temperature": 0.7,
"max_completions_tokens": 10000,
"top_p": 0.9,
"text": {
"format": {
"type": "json_schema",
"name": "python_symbols",
"schema": {
"type": "object",
"properties": {
"symbols": {
"type": "array",
"description": "A list of symbols extracted from Python code.",
"items": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the symbol."},
"symbol_type": {
"type": "string",
"description": "The type of the symbol, e.g., variable, function, class.",
},
},
"required": ["name", "symbol_type"],
"additionalProperties": False,
},
}
},
"required": ["symbols"],
"additionalProperties": False,
},
"strict": True,
},
},
},
},
)