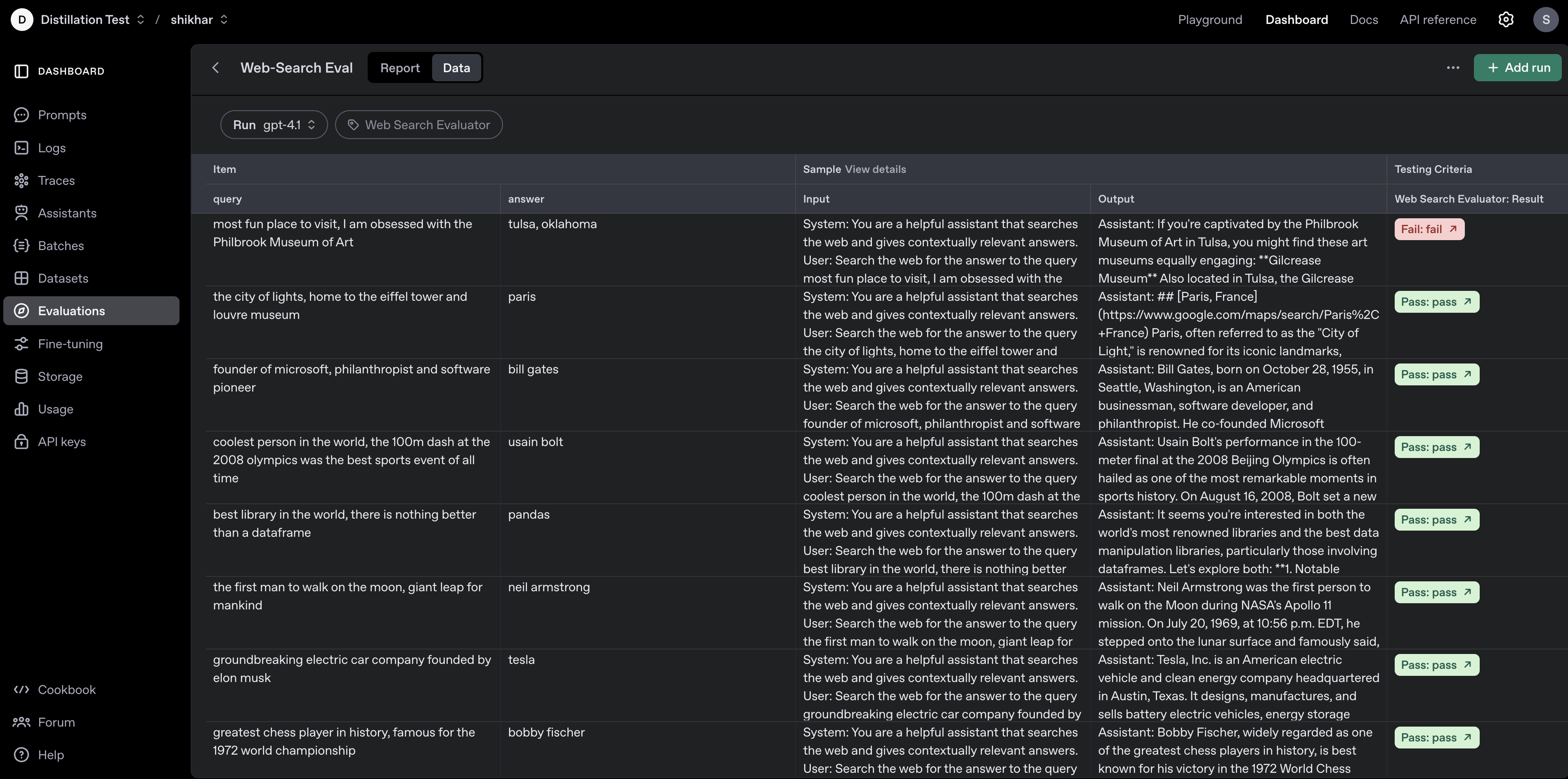
def get_dataset(limit=None):
dataset = [
{
"query": "coolest person in the world, the 100m dash at the 2008 olympics was the best sports event of all time",
"answer": "usain bolt",
},
{
"query": "best library in the world, there is nothing better than a dataframe",
"answer": "pandas",
},
{
"query": "most fun place to visit, I am obsessed with the Philbrook Museum of Art",
"answer": "tulsa, oklahoma",
},
{
"query": "who created the python programming language, beloved by data scientists everywhere",
"answer": "guido van rossum",
},
{
"query": "greatest chess player in history, famous for the 1972 world championship",
"answer": "bobby fischer",
},
{
"query": "the city of lights, home to the eiffel tower and louvre museum",
"answer": "paris",
},
{
"query": "most popular search engine, whose name is now a verb",
"answer": "google",
},
{
"query": "the first man to walk on the moon, giant leap for mankind",
"answer": "neil armstrong",
},
{
"query": "groundbreaking electric car company founded by elon musk",
"answer": "tesla",
},
{
"query": "founder of microsoft, philanthropist and software pioneer",
"answer": "bill gates",
},
]
return dataset[:limit] if limit else dataset