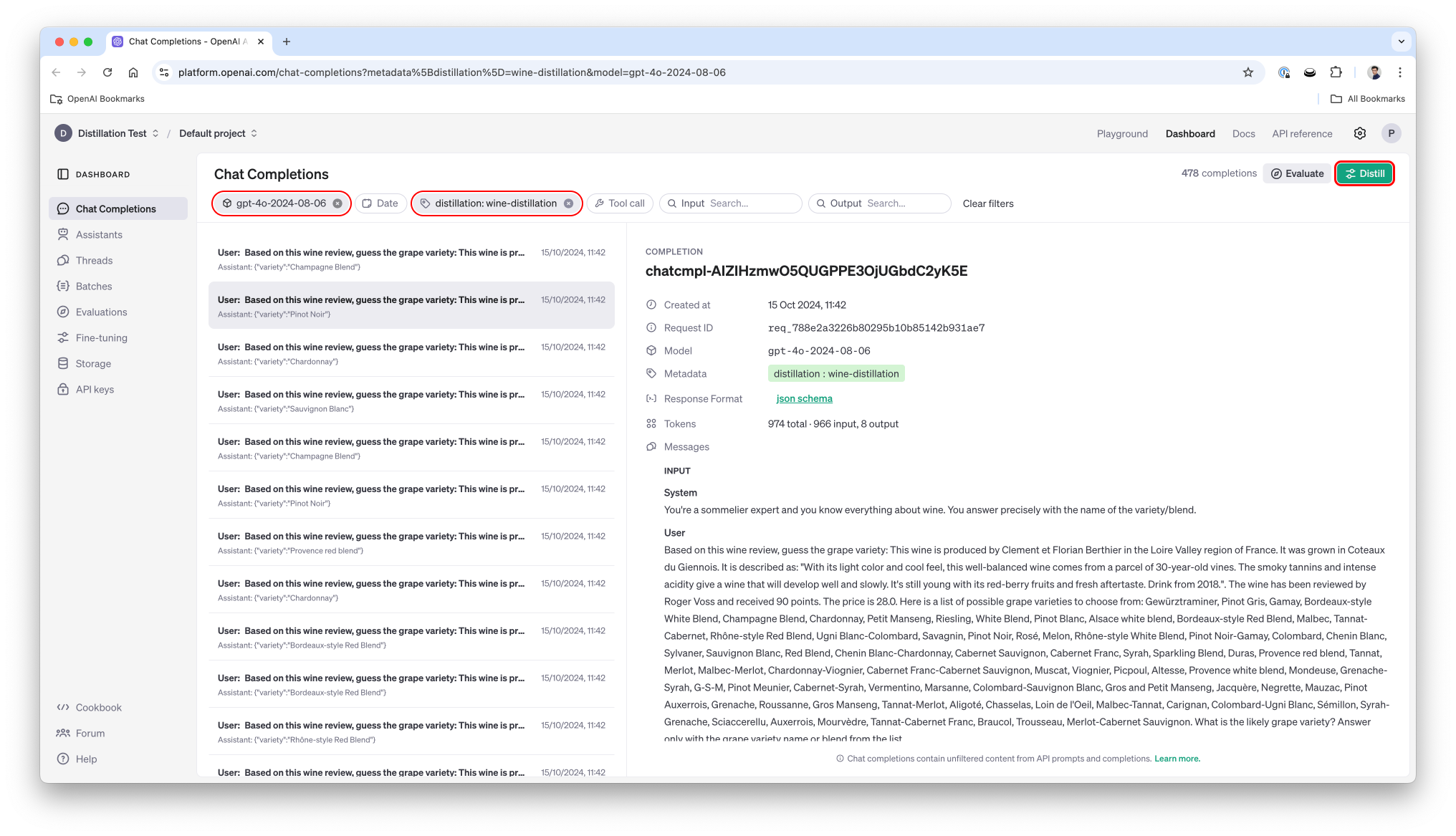
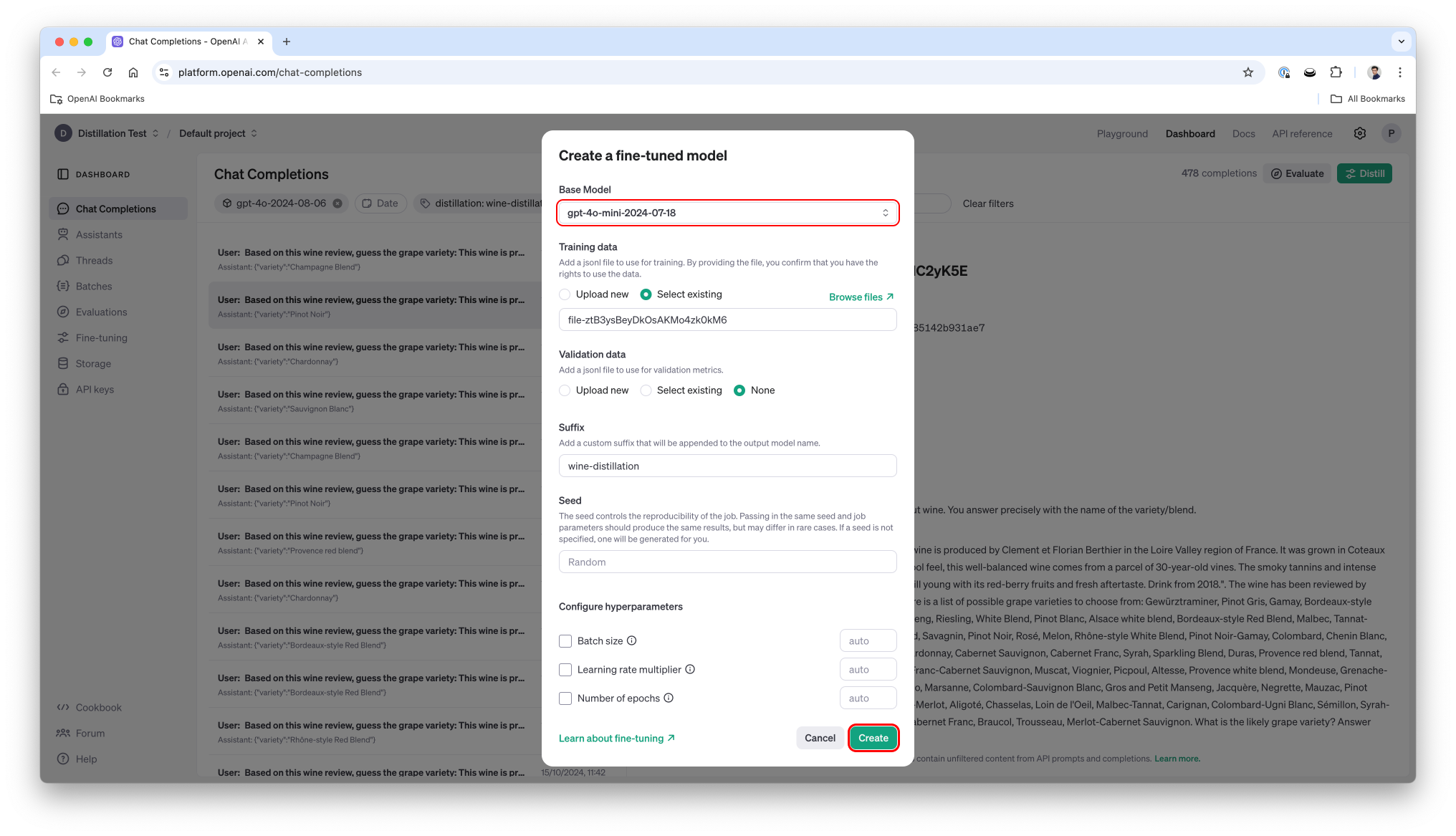
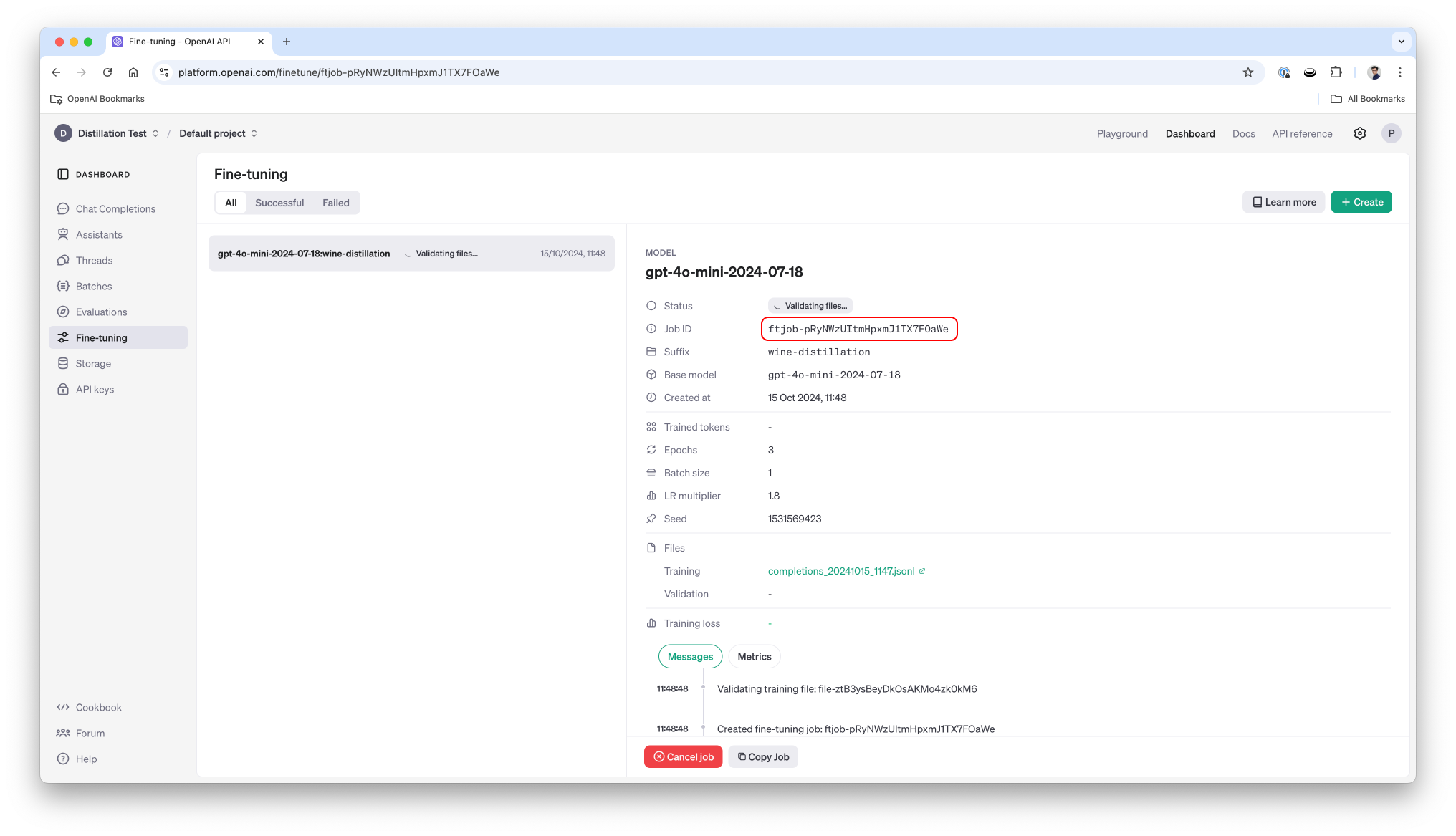
OpenAI recently released Distillation which allows to leverage the outputs of a (large) model to fine-tune another (smaller) model. This can significantly reduce the price and the latency for specific tasks as you move to a smaller model. In this cookbook we'll look at a dataset, distill the output of gpt-4o to gpt-4o-mini and show how we can get significantly better results than on a generic, non-distilled, 4o-mini.
We'll also leverage Structured Outputs for a classification problem using a list of enum. We'll see how fine-tuned model can benefit from structured output and how it will impact the performance. We'll show that Structured Ouputs work with all of those models, including the distilled one.
We'll first analyze the dataset, get the output of both 4o and 4o mini, highlighting the difference in performance of both models, then proceed to the distillation and analyze the performance of this distilled model.