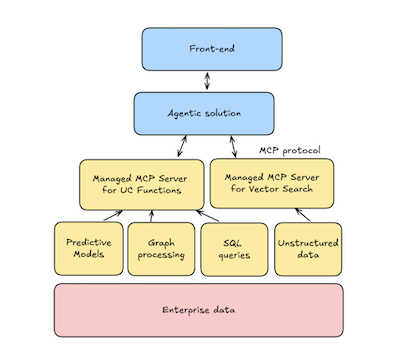
In supply-chain operations, an agent can resolve questions that directly affect service levels and revenue: Do we have the inventory and capacity to satisfy current demand? Where will manufacturing delays occur, and how will those delays propagate downstream? Which workflow adjustments will minimise disruption?
This cookbook outlines the process for building a supply-chain copilot with the OpenAI Agent SDK and Databricks Managed MCP. MCP enables the agent to query structured and unstructured enterprise data, such as inventory, sales, supplier feeds, local events, and more, for real-time visibility, early detection of material shortages, and proactive recommendations. An orchestration layer underpins the system, unifying:
Queries against structured inventory, demand, and supplier data
Time series forecasting for every wholesaler
Graph based raw material requirements and transport optimizations
Vector-indexed e-mail archives that enable semantic search across unstructured communications
Revenue risk calculation
By the end of this guide you will deploy a template that queries distributed data sources, predictive models, highlights emerging bottlenecks, and recommends proactive actions. It can address questions such as:
What products are dependent on L6HUK material?
How much revenue is at risk if we can’t produce the forecasted amount of product autoclave_1?
Which products have delays right now?
Are there any delays with syringe_1?
What raw materials are required for syringe_1?
Are there any shortages with one of the following raw materials: O4GRQ, Q5U3A, OAIFB or 58RJD?
What are the delays associated with wholesaler 9?
Stakeholders can submit a natural-language prompt and receive answers instantly.
This guide walks you through each step to implement this solution in your own environment.
The architecture presented in this cookbook layers an OpenAI Agent on top of your existing analytics workloads in Databricks. You can expose Databricks components as callable Unity Catalog functions. The agent is implemented with the OpenAI Agent SDK and connects to Databricks Managed MCP servers.
The result is a single, near-real-time conversational interface that delivers fine-grained forecasts, dynamic inventory recommendations, and data-driven decisions across the supply chain. The architecture yields an agent layer that harnesses your existing enterprise data (structured and unstructured), classical ML models, and graph-analytics capabilities.
You can set up your Databricks authentication by adding a profile to ~/.databrickscfg. A Databricks configuration profile contains settings and other information that Databricks needs to authenticate.
The snippet’s WorkspaceClient(profile=...) call will pick that up. It tells the SDK which of those stored credentials to load, so that your code never needs to embed tokens. Another option would be to create environment variables such as DATABRICKS_HOST and DATABRICKS_TOKEN, but using ~/.databrickscfg is recommended.
Generate a workspace personal access token (PAT) via Settings → Developer → Access tokens → Generate new token, then record it in ~/.databrickscfg.
To create this Databricks configuration profile file, run the Databricks CLI databricks configure command, or follow these steps:
If ~/.databrickscfg is missing, create it: touch ~/.databrickscfg
Open the file: nano ~/.databrickscfg
Insert a profile section that lists the workspace URL and personal-access token (PAT) (additional profiles can be added at any time):
[DEFAULT]host=https://dbc-a1b2345c-d6e7.cloud.databricks.com# add your workspace URL heretoken=dapi123...# add your PAT here
You can then run this sanity check command databricks clusters list with the Databricks CLI or SDK. If it returns data without prompting for credentials, the host is correct and your token is valid.
As a pre-requisite, Serverless compute and Unity Catalog must be enabled in the Databricks workspace.
This cookbook can be used to work with your own Databricks supply chain datasets and analytical workloads.
Alternatively, you can accelerate your setup by using a tailored version of the Databricks’ Supply Chain Optimization Solution Accelerator. To do so, you can clone this GitHub repository into your Databricks workspace and follow the instructions in the README file. Running the solution will stand up every asset the Agent will later reach via MCP, from raw enterprise tables and unstructured e-mails to classical ML models and graph workloads.
If you prefer to use your own datasets and models, make sure to wrap relevant components as Unity Catalog functions and define a Vector Search index as shown in the accelerator. You can also expose Genie Spaces.
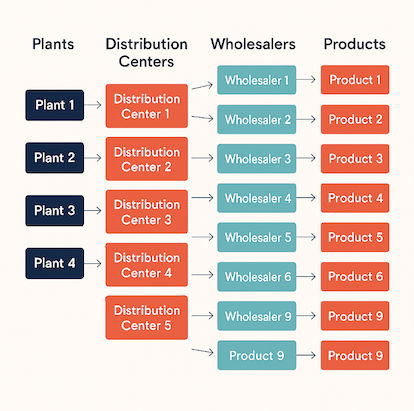
The sample data mirrors a realistic pharma network: three plants manufacture 30 products, ship them to five distribution centers, and each distribution center serves 30-60 wholesalers. The repo ships time-series demand for every product-wholesaler pair, a distribution center-to-wholesaler mapping, a plant-to-distribution center cost matrix, plant output caps, and an e-mail archive flagging shipment delays.
Answering supply-chain operations questions requires modelling how upstream bottlenecks cascade through production, logistics, and fulfilment so that stakeholders can shorten lead times, avoid excess stock, and control costs. The notebooks turn these raw feeds into governed, callable artefacts:
Demand forecasting & aggregation (notebook 2): Generates one-week-ahead SKU demand for every wholesaler and distribution center with a Holt-Winters seasonal model (or any preferred time-series approach). It leverages Spark’s parallelisation for large-scale forecasting tasks by using Pandas UDFs (taking your single node data science code and distributing it across multiple nodes). Forecasts are then rolled up to DC-level totals for each product. The output is a table product_demand_forecasted with aggregate forecasts at the distribution center level.
Raw-material planning (notebook 3): Constructs a product-to-material using graph processing, propagating demand up the bill-of-materials hierarchy to calculate component requirements at scale. We transform the bill‑of‑materials into a graph so product forecasts can be translated into precise raw‑material requirements, yielding two tables: raw_material_demand and raw_material_supply.
Transportation optimisation (notebook 4): Minimises plant to distribution center transportation cost under capacity and demand constraints, leveraging Pandas UDFs, outputting recommendations in shipment_recommendations.
Semantic e-mail search (notebook 6): Embeds supply-chain manager e-mails in a vector index using OpenAI embedding models, enabling semantic queries that surface delay and risk signals.
Each insight is wrapped as a Unity Catalog (UC) function in notebook 5 and notebook 7, e.g. product_from_raw, raw_from_product, revenue_risk, lookup_product_demand, query_unstructured_emails. Because UC governs tables, models, and vector indexes alike, the Agent can decide at runtime whether to forecast, trace a BOM dependency, gauge revenue impact, fetch history, or search e-mails, always within the caller’s data-access rights.
The result is an end-to-end pipeline that forecasts demand, identifies raw‑material gaps, optimizes logistics, surfaces hidden risks, and lets analysts ask ad‑hoc questions and surface delay warnings.
After all notebooks have been executed (by running notebook 1), the Databricks environment is ready, you can proceed to build the Agent and connect it to Databricks.
Currently, the MCP spec defines three kinds of servers, based on the transport mechanism they use:
stdio servers run as a subprocess of your application. You can think of them as running "locally".
HTTP over SSE servers run remotely. You connect to them via a URL.
Streamable HTTP servers run remotely using the Streamable HTTP transport defined in the MCP spec.
Databricks-hosted MCP endpoints (vector-search, Unity Catalog functions, Genie) sit behind standard HTTPS URLs and implement the Streamable HTTP transport defined in the MCP spec. Make sure that your workspace is serverless enabled so that you can connect to the Databricks managed MCP.
The OpenAI Agent is available here. Start by installing the required dependencies:
pip install -r requirements.txt
You will need an OpenAI API key to securely access the API. If you're new to the OpenAI API, sign up for an account. You can follow these steps to create a key and store it in a safe location.
This cookbook shows how to serve this Agent with FastAPI and chat through a React UI. However, main.py is set up as a self‑contained REPL, so after installing the required dependencies and setting up the necessary credentials (including the Databricks host and personal-access token as described above), you can run the Agent directly from the command line with a single command:
python main.py
The main.py file orchestrates the agent logic, using the OpenAI Agent SDK and exposing Databricks MCP vector-search endpoints and Unity Catalog functions as callable tools. It starts by reading environment variables that point to the target catalog, schema, and Unity Catalog (UC) function path, then exposes two tools: vector_search, which queries a Databricks Vector Search index, and uc_function, which executes Unity Catalog functions via MCP. Both tools make authenticated, POST requests through httpx, returning raw JSON from the Databricks REST API. Both helpers obtain the workspace host and Personal Access Token through the _databricks_ctx() utility (backed by DatabricksOAuthClientProvider) and issue authenticated POST requests with httpx, returning raw JSON responses.
Inside run_agent(), the script instantiates an Agent called “Assistant” that is hard-scoped to supply-chain topics. Every response must invoke one of the two registered tools, and guardrails force the agent to refuse anything outside logistics, inventory, procurement or forecasting. Each user prompt is processed inside an SDK trace context. A simple REPL drives the interaction: user input is wrapped in an OpenTelemetry-style trace, dispatched through Runner.run, and the final answer (or guardrail apology) is printed. The program is kicked off through an asyncio.run call in main(), making the whole flow fully asynchronous and non-blocking.
"""CLI assistant that uses Databricks MCP Vector Search and UC Functions via the OpenAI Agents SDK."""import asyncioimport osimport httpxfrom typing import Dict, Anyfrom agents import Agent, Runner, function_tool, gen_trace_id, tracefrom agents.exceptions import ( InputGuardrailTripwireTriggered, OutputGuardrailTripwireTriggered,)from agents.model_settings import ModelSettingsfrom databricks_mcp import DatabricksOAuthClientProviderfrom databricks.sdk import WorkspaceClientfrom supply_chain_guardrails import supply_chain_guardrailCATALOG= os.getenv("MCP_VECTOR_CATALOG", "main") # override catalog, schema, functions_path name if your data assets sit in a different locationSCHEMA= os.getenv("MCP_VECTOR_SCHEMA", "supply_chain_db")FUNCTIONS_PATH= os.getenv("MCP_FUNCTIONS_PATH", "main/supply_chain_db")DATABRICKS_PROFILE= os.getenv("DATABRICKS_PROFILE", "DEFAULT") # override if using a different profile name HTTP_TIMEOUT=30.0# secondsasyncdef_databricks_ctx():"""Return (workspace, PAT token, base_url).""" ws = WorkspaceClient(profile=DATABRICKS_PROFILE) token = DatabricksOAuthClientProvider(ws).get_token()return ws, token, ws.config.host@function_toolasyncdefvector_search(query: str) -> Dict[str, Any]:"""Query Databricks MCP Vector Search index.""" ws, token, base_url =await _databricks_ctx() url =f"{base_url}/api/2.0/mcp/vector-search/{CATALOG}/{SCHEMA}" headers = {"Authorization": f"Bearer {token}"}asyncwith httpx.AsyncClient(timeout=HTTP_TIMEOUT) as client: resp =await client.post(url, json={"query": query}, headers=headers) resp.raise_for_status()return resp.json()@function_toolasyncdefuc_function(function_name: str, params: Dict[str, Any]) -> Dict[str, Any]:"""Invoke a Databricks Unity Catalog function with parameters.""" ws, token, base_url =await _databricks_ctx() url =f"{base_url}/api/2.0/mcp/functions/{FUNCTIONS_PATH}" headers = {"Authorization": f"Bearer {token}"} payload = {"function": function_name, "params": params}asyncwith httpx.AsyncClient(timeout=HTTP_TIMEOUT) as client: resp =await client.post(url, json=payload, headers=headers) resp.raise_for_status()return resp.json()asyncdefrun_agent(): agent = Agent(name="Assistant",instructions="You are a supply-chain assistant for Databricks MCP; you must answer **only** questions that are **strictly** about supply-chain data, logistics, inventory, procurement, demand forecasting, etc; for every answer you must call one of the registered tools; if the user asks anything not related to supply chain, reply **exactly** with 'Sorry, I can only help with supply-chain questions'.",tools=[vector_search, uc_function],model_settings=ModelSettings(model="gpt-4o", tool_choice="required"),output_guardrails=[supply_chain_guardrail], )print("Databricks MCP assistant ready. Type a question or 'exit' to quit.")whileTrue: user_input =input("You: ").strip()if user_input.lower() in {"exit", "quit"}:break trace_id = gen_trace_id()with trace(workflow_name="Databricks MCP Agent", trace_id=trace_id):try: result =await Runner.run(starting_agent=agent, input=user_input)print("Assistant:", result.final_output)except InputGuardrailTripwireTriggered:print("Assistant: Sorry, I can only help with supply-chain questions.")except OutputGuardrailTripwireTriggered:print("Assistant: Sorry, I can only help with supply-chain questions.")defmain(): asyncio.run(run_agent())if__name__=="__main__": main()
databricks_mcp.py serves as a focused authentication abstraction: it obtains the Personal Access Token we created earlier from a given WorkspaceClient (ws.config.token) and shields the rest of the application from Databricks‑specific OAuth logic. By confining all token‑handling details to this single module, any future changes to Databricks’ authentication scheme can be accommodated by updating this file.
"""Databricks OAuth client provider for MCP servers."""classDatabricksOAuthClientProvider:def__init__(self, ws):self.ws = wsdefget_token(self):# For Databricks SDK >=0.57.0, token is available as ws.config.tokenreturnself.ws.config.token
supply_chain_guardrails.py implements a lightweight output guardrail by spinning up a second agent (“Supply‑chain check”) that classifies candidate answers. The main agent hands its draft reply to this checker, which returns a Pydantic object with a Boolean is_supply_chain. If that flag is false, the guardrail raises a tripwire and the caller swaps in a refusal.
"""Output guardrail that blocks answers not related to supply-chain topics."""from__future__import annotationsfrom pydantic import BaseModelfrom agents import Agent, Runner, GuardrailFunctionOutputfrom agents import output_guardrailfrom agents.run_context import RunContextWrapperclassSupplyChainCheckOutput(BaseModel): reasoning: str is_supply_chain: boolguardrail_agent = Agent(name="Supply-chain check",instructions=("Check if the text is within the domain of supply-chain analytics and operations ""Return JSON strictly matching the SupplyChainCheckOutput schema" ),output_type=SupplyChainCheckOutput,)@output_guardrailasyncdefsupply_chain_guardrail( ctx: RunContextWrapper, agent: Agent, output) -> GuardrailFunctionOutput:"""Output guardrail that blocks non-supply-chain answers""" text = output ifisinstance(output, str) elsegetattr(output, "response", str(output)) result =await Runner.run(guardrail_agent, text, context=ctx.context)return GuardrailFunctionOutput(output_info=result.final_output,tripwire_triggered=not result.final_output.is_supply_chain, )
The api_server.py is a FastAPI backend that exposes your agent as a streaming /chat API endpoint. At startup it configures CORS so a local front-end can talk to it, then defines build_mcp_servers(), which authenticates to the caller’s Databricks workspace, constructs two HTTP “server tools” (one for vector search, one for Unity-Catalog functions), and pre-connects them for low-latency use. Each incoming POST to /chat contains a single user message. The handler spins up a fresh Agent whose mcp_servers list is populated by those streaming tools and whose model is forced to call a tool for every turn.
"""FastAPI wrapper that exposes the agent as a streaming `/chat` endpoint."""import osimport asyncioimport loggingfrom fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom fastapi.middleware.cors import CORSMiddlewarefrom pydantic import BaseModelfrom agents.exceptions import ( InputGuardrailTripwireTriggered, OutputGuardrailTripwireTriggered,)from agents import Agent, Runner, gen_trace_id, tracefrom agents.mcp import MCPServerStreamableHttp, MCPServerStreamableHttpParamsfrom agents.model_settings import ModelSettingsfrom databricks_mcp import DatabricksOAuthClientProviderfrom databricks.sdk import WorkspaceClientfrom supply_chain_guardrails import supply_chain_guardrailCATALOG= os.getenv("MCP_VECTOR_CATALOG", "main")SCHEMA= os.getenv("MCP_VECTOR_SCHEMA", "supply_chain_db")FUNCTIONS_PATH= os.getenv("MCP_FUNCTIONS_PATH", "main/supply_chain_db")DATABRICKS_PROFILE= os.getenv("DATABRICKS_PROFILE", "DEFAULT")HTTP_TIMEOUT=30.0# secondsapp = FastAPI()# Allow local dev front‑endapp.add_middleware( CORSMiddleware,allow_origins=["http://localhost:5173"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)classChatRequest(BaseModel): message: strasyncdefbuild_mcp_servers():"""Initialise Databricks MCP vector & UC‑function servers.""" ws = WorkspaceClient(profile=DATABRICKS_PROFILE) token = DatabricksOAuthClientProvider(ws).get_token() base = ws.config.host vector_url =f"{base}/api/2.0/mcp/vector-search/{CATALOG}/{SCHEMA}" fn_url =f"{base}/api/2.0/mcp/functions/{FUNCTIONS_PATH}"asyncdef_proxy_tool(request_json: dict, url: str):import httpx headers = {"Authorization": f"Bearer {token}"}asyncwith httpx.AsyncClient(timeout=HTTP_TIMEOUT) as client: resp =await client.post(url, json=request_json, headers=headers) resp.raise_for_status()return resp.json() headers = {"Authorization": f"Bearer {token}"} servers = [ MCPServerStreamableHttp( MCPServerStreamableHttpParams(url=vector_url,headers=headers,timeout=HTTP_TIMEOUT, ),name="vector_search",client_session_timeout_seconds=60, ), MCPServerStreamableHttp( MCPServerStreamableHttpParams(url=fn_url,headers=headers,timeout=HTTP_TIMEOUT, ),name="uc_functions",client_session_timeout_seconds=60, ), ]# Ensure servers are initialized before useawait asyncio.gather(*(s.connect() for s in servers))return servers@app.post("/chat")asyncdefchat_endpoint(req: ChatRequest):try: servers =await build_mcp_servers() agent = Agent(name="Assistant",instructions="Use the tools to answer the questions.",mcp_servers=servers,model_settings=ModelSettings(tool_choice="required"),output_guardrails=[supply_chain_guardrail], ) trace_id = gen_trace_id()asyncdefagent_stream(): logging.info(f"[AGENT_STREAM] Input message: {req.message}")try:with trace(workflow_name="Databricks MCP Example", trace_id=trace_id): result =await Runner.run(starting_agent=agent, input=req.message) logging.info(f"[AGENT_STREAM] Raw agent result: {result}")try: logging.info(f"[AGENT_STREAM] RunResult __dict__: {getattr(result, '__dict__', str(result))}" ) raw_responses =getattr(result, "raw_responses", None) logging.info(f"[AGENT_STREAM] RunResult raw_responses: {raw_responses}")exceptExceptionas log_exc: logging.warning(f"[AGENT_STREAM] Could not log RunResult details: {log_exc}")yield result.final_outputexcept InputGuardrailTripwireTriggered:# Off-topic question denied by guardrailyield"Sorry, I can only help with supply-chain questions."except OutputGuardrailTripwireTriggered:# Out-of-scope answer blocked by guardrailyield"Sorry, I can only help with supply-chain questions."exceptException: logging.exception("[AGENT_STREAM] Exception during agent run")yield"[ERROR] Exception during agent run. Check backend logs for details."return StreamingResponse(agent_stream(), media_type="text/plain")exceptException: logging.exception("chat_endpoint failed")return StreamingResponse( (line.encode() for line in ["Internal server error 🙈"]),media_type="text/plain",status_code=500, )
The endpoint streams tokens back to the browser while the agent reasons and calls MCP tools.
The React chat UI in the /ui folder provides a user-friendly web interface for interacting with the backend agent. It features components for displaying the conversation history and a text input for sending messages.
When a user submits a message, the UI sends it to the backend /chat endpoint and streams the agent’s response in real time, updating the chat window as new content arrives. The design emphasizes a conversational experience, making it easy for users to ask questions and receive answers from the Databricks-powered agent, all within a responsive and interactive web application.
In particular, the file ChatUI.jsx file contains the core logic for the chat interface, including how user messages are sent to the backend and how streaming responses from the agent are handled and displayed in real time.
"""Code snippet handling the token stream coming from the FastAPI /chat endpoint."""const reader = response.body.getReader();while (true) { const { done, value } = await reader.read();if (done) break; assistantMsg.text += new TextDecoder().decode(value); setMessages(m=> { const copy = [...m]; copy[copy.length -1] = { ...assistantMsg };return copy; });}
The UI streams and displays the agent’s response as it arrives, creating a smooth, real-time chat experience. Highlighting this will clearly show your readers how the UI achieves interactive, conversational feedback from your backend agent.
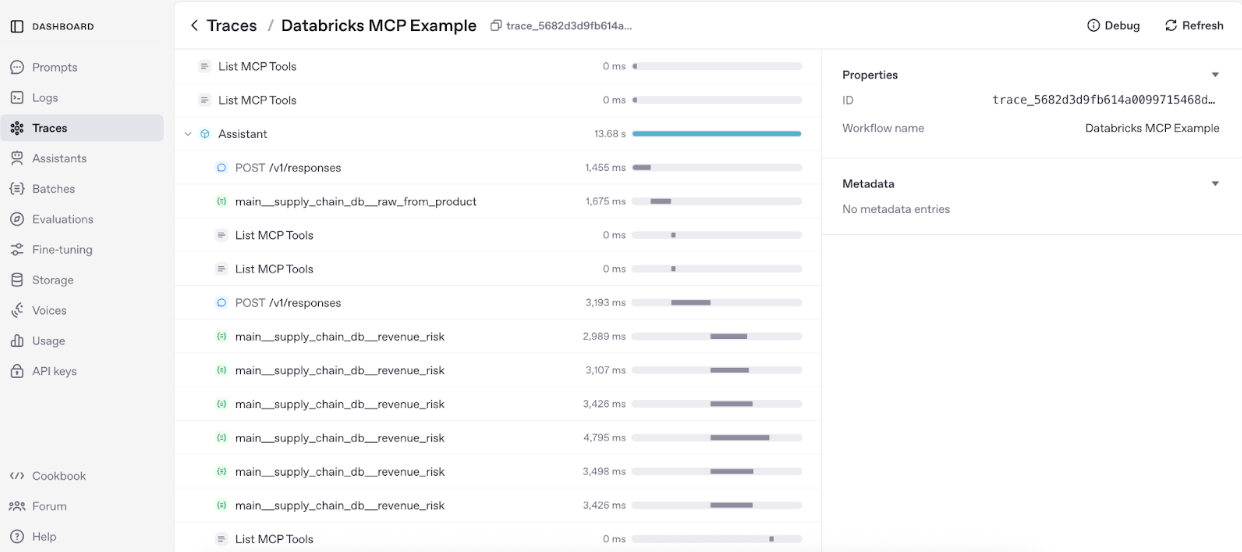
In the OpenAI API dashboard you can open the Traces view to see every function the agent invoked. In the example below, the agent first calls raw_from_product to fetch the material linked to a specific product, and then calls revenue_risk to estimate the revenue impact of a shortage.