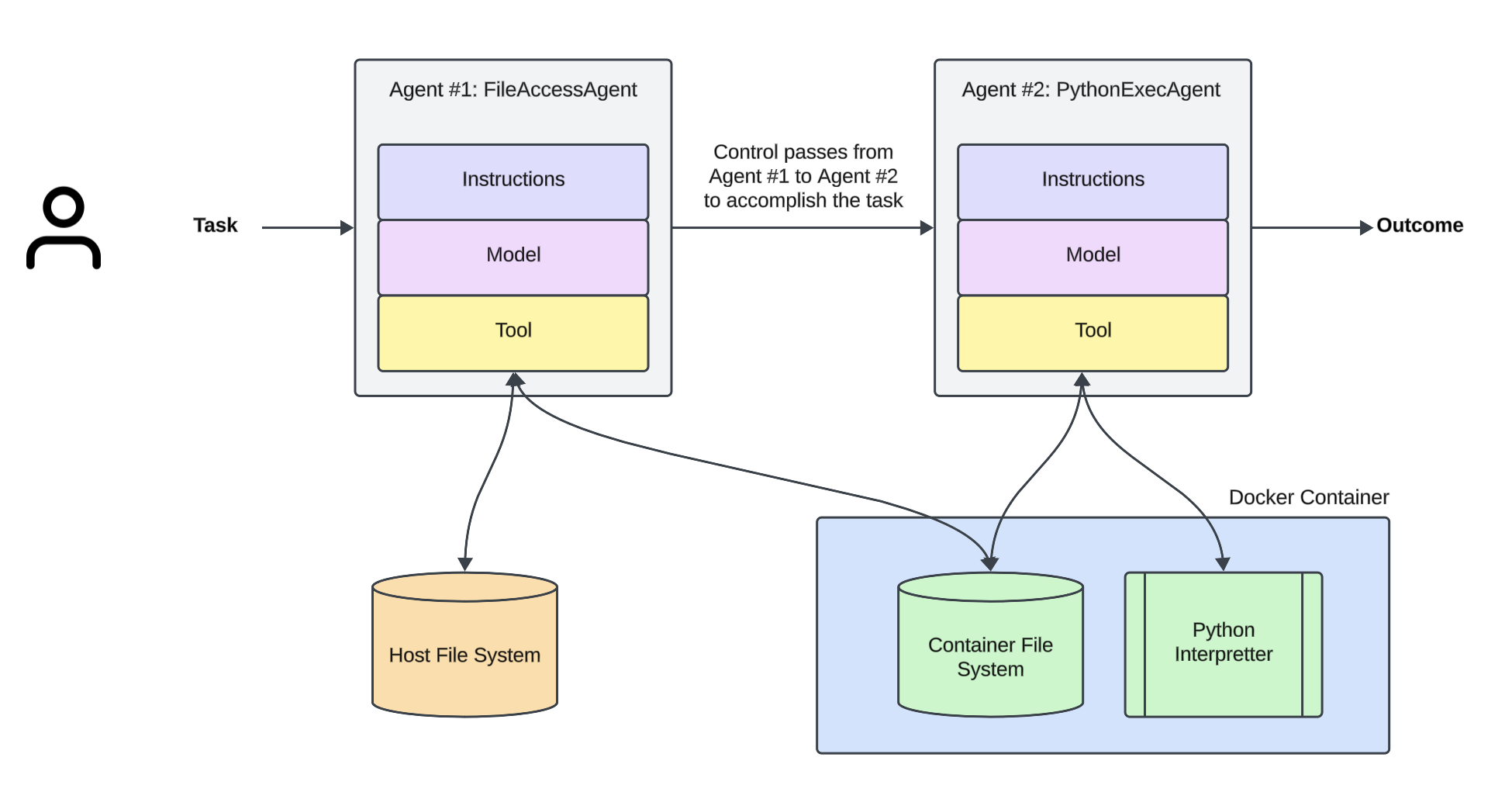
At the core of providing a LLM Agent capability to interact with the outside world or other Agents is “tool (or function) calling,” where a LLM can invoke a function (a block of code) with arguments. Typically, these functions are predefined by the developer, along with their expected inputs and outputs. However, in this Cookbook, we explore a more flexible paradigm - to dynamically generate tools using LLM models (in this case o3-mini), with ability to execute the tool using a code interpreter.
A Dynamically Generated Tool is a function or code block created by the LLM itself at runtime based on the user’s prompt. This means you don’t have to predefine every possible scenario in your codebase—enabling far more open-ended, creative, and adaptive problem-solving.
Dynamically Generated Tool Calling goes a step further by granting the LLM the ability to generate tools and execute code blocks on the fly. This dynamic approach is particularly useful for tasks that involve:
Data analysis and visualization
Data manipulation and transformation
Machine learning workflow generation and execution
Process automation and scripting
And much more, as new possibilities emerge through experimentation
Released on 31-Jan-25, o3-mini model has exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of smaller models. In this Cookbook, we will demonstrate o3-mini's capabilities to generate python code to interpret data and draw insights.
Reasoning models are particularly good at generating dynamic tools to analyze data since they can reason on their own, without the need of an explicit chain-of-thought prompt. In fact, providing explicit chain of thought instructions may interfere with model's internal reasoning and lead to suboptimal outcomes. You can learn more about o3-mini here.
Many API providers—such as OpenAI’s Assistants API—offer built-in code interpreter functionality. These built-in code interpreters can be immensely powerful, but there are situations where developers may need to create their own custom code interpreter. For example:
Language or library support: The built-in interpreter may not support the specific programming language (e.g., C++, Java, etc.) or libraries required for your task.
Task compatibility: Your use case may not be compatible with the provider’s built-in solution.
Model constraints: You might require a language model that isn’t supported by the provider’s interpreter.
Cost considerations: The cost structure for code execution or model usage may not fit your budget or constraints.
File size: The file size of input data is too large or not supported by the provider's interpreter.
Integrating with internal systems: The provider's interpreter may not be able to integrate with your internal systems.
By following this Cookbook, you will learn how to:
Set up an isolated Python code execution environment using Docker
Configure your own code interpreter tool for LLM agents
Establish a clear separation of “Agentic” concerns for security and safety
Using o3-mini model to dynamically generate code for data analysis
Orchestrate agents to efficiently accomplish a given task
Design an agentic application that can dynamically generate and execute code
You’ll learn how to build a custom code interpreter tool from the ground up, leverage the power of LLMs to generate sophisticated code, and safely execute that code in an isolated environment—all in pursuit of making your AI-powered applications more flexible, powerful, and cost-effective.
We'll use the sample data provided at Key Factors Traffic Accidents to answer a set of questions. These questions do not require to be pre-defined, we will give LLM the ability to generate code to answer such question.
Sample questions could be:
What factors contribute the most to accident frequency? (Feature importance analysis)
Which areas are at the highest risk of accidents? (Classification/Clustering)
How does traffic fine amount influence the number of accidents? (Regression/Causal inference)
Can we determine the optimal fine amounts to reduce accident rates? (Optimization models)
Do higher fines correlate with lower average speeds or reduced accidents? (Correlation/Regression)
and so on ...
Using the traditional Predefined Tool Calling approach, developer would need to pre-define the function for each of these questions. This limits the LLM's ability to answer any other questions not defined in the pre-defined set of functions. We overcome this limitation by using the Dynamic Tool Calling approach where the LLM generates code and uses a Code Interpretter tool to execute the code.
We need a secure environment where our LLM generated function calls can be executed. We want to avoid directly running the LLM generated code on the host machine so will create a Docker container environment with restricted resource access (e.g., no network access). By default, Docker containers cannot access the host machine’s file system, which helps ensure that any code generated by the LLM remains contained.
LLMs could generate harmful code with unintended consequences. As a best practice, isolate the code execution environment with only required access to resources as needed by the task. Avoid running the LLM generated code on your host machine or laptop.
There are various ways to orchestrate the Agents based on the application requirements. In this example, we will use a simple orchestration where the user provides a task and the agents are called in sequence to accomplish the task.
Before you begin, ensure you have the following installed and configured on your host machine:
Docker: installed and running on your local machine. You can learn more about Docker and install it from here.
Python: installed on your local machine. You can learn more about Python and install it from here.
OpenAI API key: set up on your local machine as an environment variable or in the .env file in the root directory. You can learn more about OpenAI API key and set it up from here.
Lets define a Dockerized container environment that will be used to execute our code. I have defined the dockerfile under resources/docker directory that will be used to create the container environment with the following specifications:
Python 3.10 as the base
A non-root user
Preinstall the packages in requirements.txt
The requirements.txt included in the docker image creation process contains all the potential packages our LLM generated code may need to accomplish its tasks. Given we will restrict the container from network access, so we need to pre-install the packages that are required for the task. Our LLM will not be allowed to install any additional packages for security purposes.
You could create your own docker image with the language requirements (such as Python 3.10) and pre-install the packages that are required for the task, or create a custom docker image with the specific language (such as Java, C++, etc.) and packages that are required for the task.
Let's build the docker image with the following command. For the sake of brevity, I have redirected the output to grep the success message and print a message if the build fails.
Let's run the container in restricted mode. The container will run in the background. This is our opportunity to define the security policies for the container. It is good practice to only allow the bare minimum features to the container that are required for the task. By default, the container cannot access the host file system from within the container. Let's also restrict its access to network so it cannot access the Internet or any other network resources.
# Run the container in restricted mode. The container will run in the background.!docker run -d --name sandbox --network none --cap-drop all--pids-limit 64--tmpfs /tmp:rw,size=64M python_sandbox:latest sleep infinity
Instructions to understand the contents of the file to provide as context to Agent 2.
Has access to the host machine’s file system.
Can read a file from the host and copy it into the Docker container.
Cannot access the code interpreter tool.
Uses gpt-4o model.
Agent 2: Python Code Generator and Executor (with Dynamically Generated Tool Calling and Code Execution)
Recieve the file content's context from Agent 1.
Instructions to generate a Python script to answer the user's question.
Has access to the code interpreter within the Docker container, which is used to execute Python code.
Has access only to the file system inside the Docker container (not the host).
Cannot access the host machine’s file system or the network.
Uses our newest o3-mini model that excels at code generation.
This separation concerns of the File Access (Agent 1) and the Code Generator and Executor (Agent 2) is crucial to prevent the LLM from directly accessing or modifying the host machine.
Limit the Agent 1 to Static Tool Calling as it has access to the host file system.
Agent
Type of Tool Call
Access to Host File System
Access to Docker Container File System
Access to Code Interpreter
Agent 1: File Access
Pre-defined Tools
Yes
Yes
No
Agent 2: Python Code Generator and Executor
Dynamically Generated Tools
No
Yes
Yes
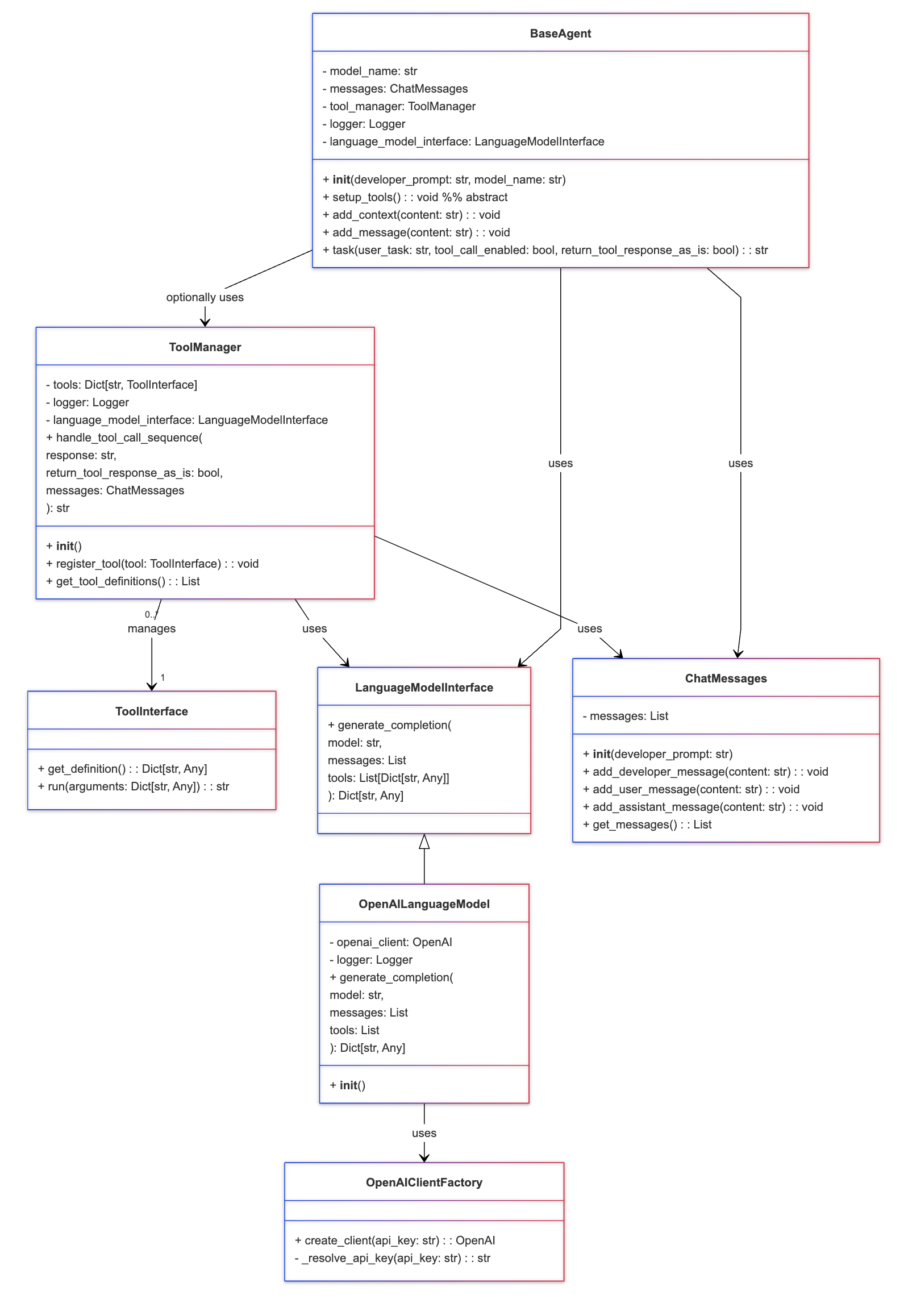
To keep the Agents and Tools organized, we've defined a set of core classes that will be used to create the two agents for consistency using Object Oriented Programming principles.
BaseAgent: We start with an abstract base class that enforces common method signatures such as task(). Base class also provides a logger for debugging, a language model interface and other common functions such as add_context() to add context to the agent.
ChatMessages: A class to store the conversation history given ChatCompletions API is stateless.
ToolManager: A class to manage the tools that an agent can call.
ToolInterface: An abstract class for any 'tool' that an agent can call so that the tools will have a consistent interface.
The following class diagram shows the relationship between the core classes. This UML (Unified Modeling Language) has been generated using Mermaid
Define Agent 1: FileAccessAgent with FileAccessTool
Let's start with definin the FileAccessTool that inherits from the ToolInterface class. The FileAccessTool tool is defined in the file_access_tool.py file in the resources/registry/tools directory.
FileAccessTool implements the ToolInterface class, which ensures that the tools will have a consistent interface.
Binding the tool definition for the OpenAI Function Calling API in the get_definition method and the tool's run method ensures maintainability, scalability, and reusability.
Now, let's define the FileAccessAgent that extends the BaseAgent class and bind the FileAccessTool to the agent. The FileAccessAgent is defined in the file_acess_agent.py file in resources/registry/agents directory. The FileAccessAgent is:
A concrete implementation of the BaseAgent class.
Initialized with the developer prompt, model name, logger, and language model interface. These values can be overridden by the developer if needed.
Has a setup_tools method that registers the FileAccessTool to the tool manager.
Has a task method that calls the FileAccessTool to read the file and provide the context to the PythonCodeExecAgent.
model_name='gpt-4o' that provides sufficient reasoning and tool calling ability for the task.
Define Agent 2: PythonExecAgent with PythonExecTool
Similarly, PythonExecTool inherits from the ToolInterface class and implements the get_definition and run methods. The get_definition method returns the tool definition in the format expected by the OpenAI Function Calling API. The run method executes the Python code in a Docker container and returns the output. This tool is defined in the python_code_interpreter_tool.py file in the resources/registry/tools directory.
Likewise, PythonExecAgent is a concrete implementation of the BaseAgent class. It is defined in the python_code_exec_agent.py file in the resources/registry/agents directory. The PythonExecAgent is:
A concrete implementation of the BaseAgent class.
Initialized with the developer prompt, model name, logger, and language model interface. These values can be overridden by the developer if needed.
Has a setup_tools method that registers the PythonExecTool to the tool manager.
Has a task method that calls the OpenAI API to perform the user's task, which in this case involves generating a Python script to answer the user's question and run it with Code Interpreter tool.
model_name='o3-mini' that excels at STEM tasks such as code generation.
reasoning_effort='high' that allows for more complete reasoning given the complexity of the task at the cost of more tokens generated and slower responses. The default value is medium, which is a balance between speed and reasoning accuracy.
You can learn more about the reasoning_effort parameter here.
With the Agents defined, now we can define the orchestration loop that will run the application. This loop will prompt the user for a question or task, and then call the FileAccessAgent to read the file and provide the context to the PythonExecAgent. The PythonExecAgent will generate the Python code to answer the user's question and execute the code in the Docker container. The output from the code execution will be displayed to the user.
User can type 'exit' to stop the application. Our question: What factors contribute the most to accident frequency? Note that we did not pre-define the function to answer this question.
# Import the agents from registry/agentsfrom resources.registry.agents.file_access_agent import FileAccessAgentfrom resources.registry.agents.python_code_exec_agent import PythonExecAgentprompt ="""Use the file traffic_accidents.csv for your analysis. The column names are:Variable Descriptionaccidents Number of recorded accidents, as a positive integer.traffic_fine_amount Traffic fine amount, expressed in thousands of USD.traffic_density Traffic density index, scale from 0 (low) to 10 (high).traffic_lights Proportion of traffic lights in the area (0 to 1).pavement_quality Pavement quality, scale from 0 (very poor) to 5 (excellent).urban_area Urban area (1) or rural area (0), as an integer.average_speed Average speed of vehicles in km/h.rain_intensity Rain intensity, scale from 0 (no rain) to 3 (heavy rain).vehicle_count Estimated number of vehicles, in thousands, as an integer.time_of_day Time of day in 24-hour format (0 to 24).accidents traffic_fine_amount"""print("Setup: ")print(prompt)print("Setting up the agents... ")# Instantiate the agents with the default constructor defined values# Developer may override the default values - prompt, model, logger, and language model interface if needed# This agent use gpt-4o by defaultfile_ingestion_agent = FileAccessAgent()# Let's make sure agent uses o3-mini model and set the reasoning_effort to highdata_analysis_agent = PythonExecAgent(model_name='o3-mini', reasoning_effort='high')print("Understanding the contents of the file...")# Give a task to the file ingestion agent to read the file and provide the context to the data analysis agent file_ingestion_agent_output = file_ingestion_agent.task(prompt)# Add the file content as context to the data analysis agent# The context is added to the agent's tool manager so that the tool manager can use the context to generate the code data_analysis_agent.add_context(prompt)data_analysis_agent.add_context(file_ingestion_agent_output)whileTrue:print("Type your question related to the data in the file. Type 'exit' to exit.") user_input =input("Type your question.")if user_input =="exit":print("Exiting the application.")breakprint(f"User question: {user_input}")print("Generating dynamic tools and using code interpreter...") data_analysis_agent_output = data_analysis_agent.task(user_input)print("Output...")print(data_analysis_agent_output)
Setup:
Use the file traffic_accidents.csv for your analysis. The column names are:
Variable Description
accidents Number of recorded accidents, as a positive integer.
traffic_fine_amount Traffic fine amount, expressed in thousands of USD.
traffic_density Traffic density index, scale from 0 (low) to 10 (high).
traffic_lights Proportion of traffic lights in the area (0 to 1).
pavement_quality Pavement quality, scale from 0 (very poor) to 5 (excellent).
urban_area Urban area (1) or rural area (0), as an integer.
average_speed Average speed of vehicles in km/h.
rain_intensity Rain intensity, scale from 0 (no rain) to 3 (heavy rain).
vehicle_count Estimated number of vehicles, in thousands, as an integer.
time_of_day Time of day in 24-hour format (0 to 24).
accidents traffic_fine_amount
Setting up the agents...
Understanding the contents of the file...
Type your question related to the data in the file. Type 'exit' to exit.
User question: What factors contribute the most to accident frequency?
Generating dynamic tools and using code interpreter...
2025-02-03 13:04:39,427 - MyApp - INFO - Handling tool call: execute_python_code
2025-02-03 13:04:39,429 - MyApp - INFO - Tool arguments: {'python_code': "import pandas as pd\nimport numpy as np\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import StandardScaler\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# Load the dataset\nfile_path = '/home/sandboxuser/traffic_accidents.csv'\ndf = pd.read_csv(file_path)\n\n# Show basic information\nprint('Dataset shape:', df.shape)\nprint('First few rows:')\nprint(df.head(), '\\n')\nprint('Columns:', df.columns.tolist(), '\\n')\n\n# Correlation matrix analysis\ncorr_matrix = df.corr()\nprint('Correlation matrix:')\nprint(corr_matrix, '\\n')\n\n# Correlation of each feature with accidents\nacc_corr = corr_matrix['accidents'].drop('accidents').sort_values(key=lambda x: abs(x), ascending=False)\nprint('Correlation of other variables with accidents (sorted by absolute correlation):')\nprint(acc_corr, '\\n')\n\n# Visualize the correlation matrix\nplt.figure(figsize=(10, 8))\nsns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')\nplt.title('Correlation Matrix')\nplt.tight_layout()\nplt.savefig('correlation_matrix.png')\nplt.close()\n\n# Prepare data for regression analysis\n# Exclude target variable 'accidents'\nfeatures = [col for col in df.columns if col != 'accidents']\nX = df[features]\ny = df['accidents']\n\n# Standardize the features to compare the regression coefficients on the same scale\nscaler = StandardScaler()\nX_scaled = scaler.fit_transform(X)\n\n# Fit a linear regression model\nmodel = LinearRegression()\nmodel.fit(X_scaled, y)\n\n# Gather coefficients along with feature names\ncoef = model.coef_\ncoef_df = pd.DataFrame({'Feature': features, 'Coefficient': coef})\ncoef_df['AbsCoefficient'] = coef_df['Coefficient'].abs()\ncoef_df = coef_df.sort_values(by='AbsCoefficient', ascending=False)\nprint('Linear Regression Coefficients (using standardized features):')\nprint(coef_df[['Feature', 'Coefficient']], '\\n')\n\n# Additionally, compute feature importances using a Random Forest regressor\nfrom sklearn.ensemble import RandomForestRegressor\nrf = RandomForestRegressor(random_state=42)\nrf.fit(X, y)\nrf_importance = rf.feature_importances_\nrf_df = pd.DataFrame({'Feature': features, 'Importance': rf_importance})\nrf_df = rf_df.sort_values(by='Importance', ascending=False)\nprint('Random Forest Feature Importances:')\nprint(rf_df, '\\n')\n\n# The printed outputs will help in understanding which factors contribute most to accident frequency.\n\n# For clarity, save the coefficients and importances to CSV files (optional)\ncoef_df.to_csv('linear_regression_coefficients.csv', index=False)\nrf_df.to_csv('random_forest_importances.csv', index=False)\n\n# End of analysis\n"}
2025-02-03 13:04:43,123 - MyApp - INFO - Tool 'execute_python_code' response: Dataset shape: (8756, 10)
First few rows:
accidents traffic_fine_amount ... vehicle_count time_of_day
0 20 4.3709 ... 290.8570 160.4320
1 11 9.5564 ... 931.8120 8.9108
2 19 7.5879 ... 830.0860 5.5727
3 23 6.3879 ... 813.1590 131.4520
4 23 2.4042 ... 1.4663 6.9610
[5 rows x 10 columns]
Columns: ['accidents', 'traffic_fine_amount', 'traffic_density', 'traffic_lights', 'pavement_quality', 'urban_area', 'average_speed', 'rain_intensity', 'vehicle_count', 'time_of_day']
Correlation matrix:
accidents traffic_fine_amount ... vehicle_count time_of_day
accidents 1.000000 -0.745161 ... 0.068399 0.101995
traffic_fine_amount -0.745161 1.000000 ... -0.016610 -0.006236
traffic_density -0.059265 -0.004365 ... -0.014244 0.002806
traffic_lights -0.026642 0.009056 ... 0.001373 -0.001971
pavement_quality 0.064694 -0.021229 ... 0.007840 0.000055
urban_area 0.145092 -0.005136 ... -0.006053 -0.006320
average_speed 0.093923 0.009151 ... 0.000777 -0.005338
rain_intensity -0.091673 -0.015302 ... -0.025933 -0.013446
vehicle_count 0.068399 -0.016610 ... 1.000000 -0.009303
time_of_day 0.101995 -0.006236 ... -0.009303 1.000000
[10 rows x 10 columns]
Correlation of other variables with accidents (sorted by absolute correlation):
traffic_fine_amount -0.745161
urban_area 0.145092
time_of_day 0.101995
average_speed 0.093923
rain_intensity -0.091673
vehicle_count 0.068399
pavement_quality 0.064694
traffic_density -0.059265
traffic_lights -0.026642
Name: accidents, dtype: float64
Linear Regression Coefficients (using standardized features):
Feature Coefficient
0 traffic_fine_amount -3.891935
4 urban_area 0.739618
5 average_speed 0.533698
6 rain_intensity -0.532251
8 time_of_day 0.512661
1 traffic_density -0.331997
7 vehicle_count 0.281283
3 pavement_quality 0.264987
2 traffic_lights -0.092800
Random Forest Feature Importances:
Feature Importance
0 traffic_fine_amount 0.580838
1 traffic_density 0.165201
6 rain_intensity 0.095124
8 time_of_day 0.035814
5 average_speed 0.035590
3 pavement_quality 0.032177
2 traffic_lights 0.022613
7 vehicle_count 0.021006
4 urban_area 0.011637
Output...
The analysis shows that one variable stands out by far:
• Both the simple correlation analysis and regression results indicate that traffic_fine_amount is the dominant factor—its correlation with accidents is strong (about –0.75), and in the standardized linear regression its coefficient is the largest in magnitude (around –3.89). The negative sign suggests that, in this data, higher fine amounts are associated with fewer accidents (which might reflect more stringent enforcement or deterrence).
Other findings include:
• The Random Forest model also ranks traffic_fine_amount as most important (importance ≈ 0.58), with the next most influential factor being traffic_density (importance ≈ 0.17). Although its simple correlation with accidents is lower, traffic_density may contribute non‐linearly.
• Additional factors like urban_area, average_speed, rain_intensity, and time_of_day have moderate associations (with linear model coefficients ranging between about ±0.5 to +0.74). These suggest that accidents tend to be somewhat higher in urban areas and vary with time of day and weather conditions, but their overall impact is much less than that of traffic fine amounts.
In summary, the data analysis indicates that traffic_fine_amount contributes the most to accident frequency—with higher fines linked to fewer recorded accidents—while factors such as traffic density, urban area status, vehicle speed, rain intensity, and time of day also play secondary roles.
Type your question related to the data in the file. Type 'exit' to exit.
Exiting the application.
In this example, the o3-mini dynamically generated a tool (Python script) based on user's question to analyze the data. Note that o3-mini examined the problem using multiple approaches such as correlation analysis, linear regression and random forest models. This approach highlights the following:
reasoning_effort: The depth of reasoning the model performs e.g., in this case number of approaches, generally increases when the parameter is increased from low, medium to high. You can try with different levels of reasoning effort to see the difference.
Dynamically Generated Tool Calling: The tool (Python script) to analyze the data was not manually written or predetermined by the developer. Instead, the o3-mini model created the relevant data exploration and correlation analysis code at runtime.
Isolated Code Execution: To ensure security and avoid running untrusted code on the host machine, the Python script was executed inside a Docker container using the execute_python_code tool. This container had restricted resource access (e.g., no network and limited filesystem access), minimizing potential risks posed by arbitrary code execution.
The Cookbook provides a guide for developing a custom code interpreter tailored to specific application needs, addressing limitations found in vendor-provided solutions such as language constraints, cost considerations, and the need for flexibility with different LLMs or models.
Approach for Managing Agents and Tools: We also defined a set of core classes to manage the agents and tools. This approach ensures that the agents and tools will have a consistent interface and can be reused across different applications. A repository of agents and tools such as the registry folder can be created to manage the agents and tools.
o3-mini model: We demonstrated o3-mini model's ability to generate sophisticated code at run time to analyze data based on user's minimal prompt. o3-mini model then reasoned over the outcome of the analysis to explain the results to the user.
Finally, to recap, the three steps to build an Agentic Application with Dynamic Tool Calling are:
Set up an isolated code execution container environment
Define and Test the Agents
Set up Agentic Orchestration to run the application
We discussed the importance of isolating the code execution environment to ensure security and avoid running untrusted code on the host machine. With the use case of a CSV file, we demonstrated how to dynamically generate a tool (a Python script) to analyze the data and answer the user's question. We also showed how to execute the code in a Docker container and return the output to the user.