Agentic systems often reach a plateau after proof-of-concept because they depend on humans to diagnose edge cases and correct failures. This cookbook introduces a repeatable retraining loop that captures those issues, learns from the feedback, and promotes improvements back into production-like workflows. We ground the approach in a regulated healthcare documentation task, but the patterns generalize to any domain that demands accuracy, auditability, and rapid iteration.
For this cookbook, we focus on a real-world use case: drafting regulatory documents for pharmaceutical companies. These organizations must prepare and submit extensive documentation to regulatory authorities (e.g., the U.S. Food and Drug Administration) to obtain approval for new drugs. The accuracy and speed of these submissions are critical, as they directly impact how quickly life-saving treatments can reach patients.
Regulatory document drafting is a highly complex, iterative, and precision-driven process that requires deep scientific, medical, and compliance expertise. Despite the availability of advanced authoring tools, it remains labor-intensive and prone to human error. Agentic systems offer substantial leverage by assisting with research synthesis, content generation, and document structuring, yet human experts are still needed to ensure factual accuracy and regulatory compliance.
The key challenge is to design a feedback loop that enables these agentic systems to learn iteratively and refine model behavior over time. Such a system can gradually shift human effort from detailed correction to high-level oversight, improving efficiency while maintaining the rigorous standards required for regulatory submissions.
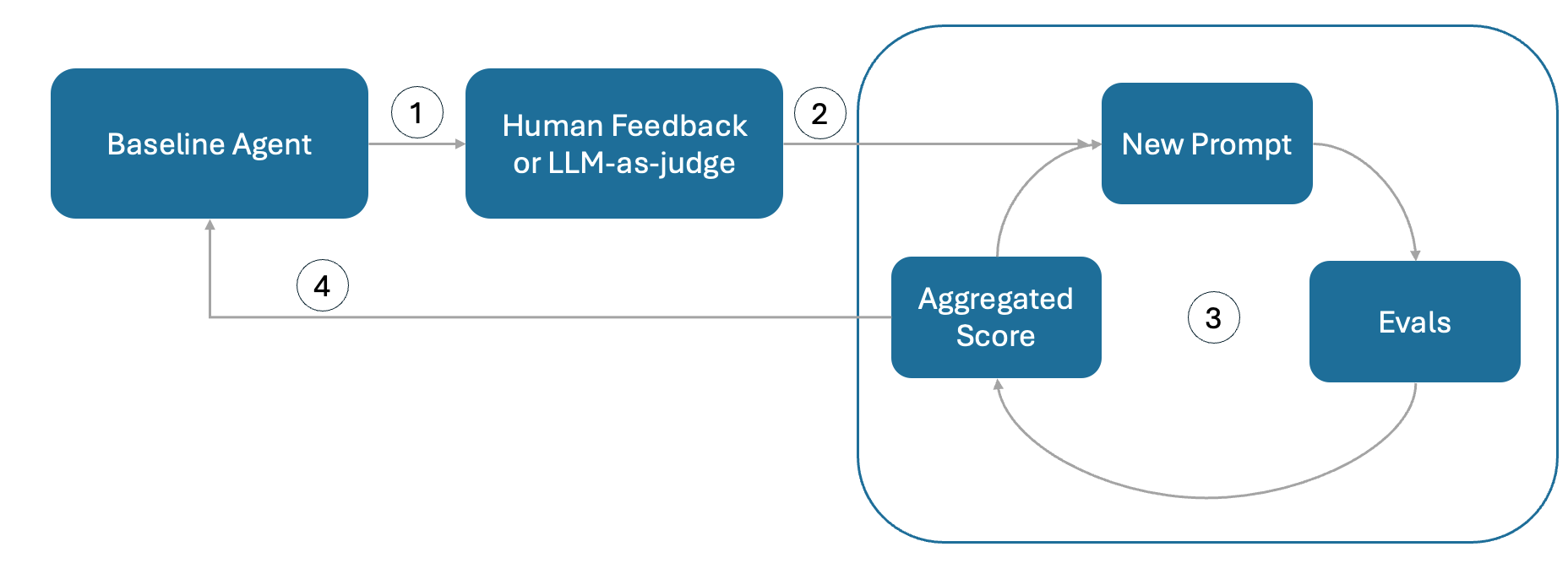
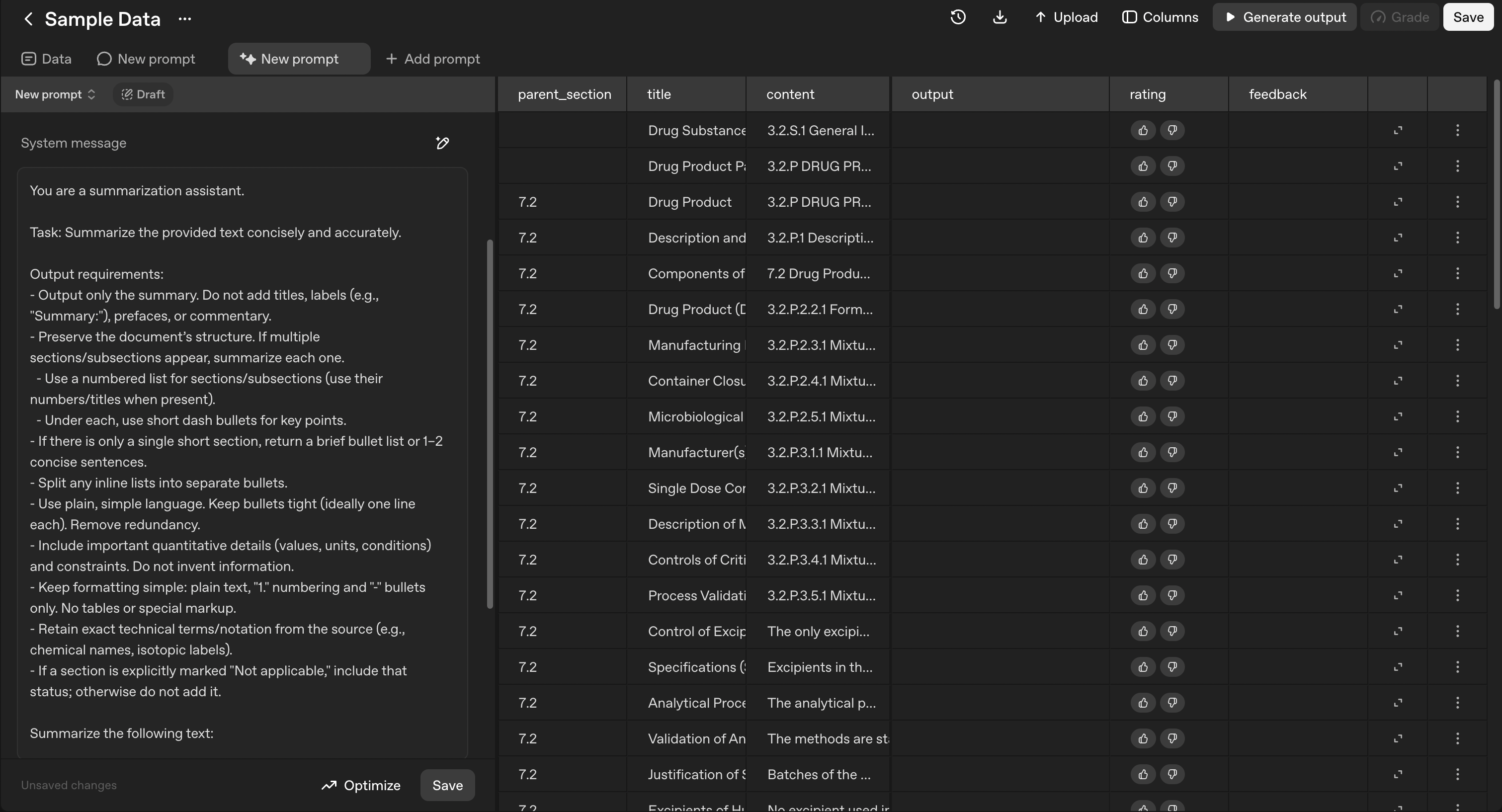
The diagram below illustrates the iterative process for continuously improving an AI agent through feedback, meta prompting, and evaluation. The loop combines human judgment or automated feedback using an LLM-as-a-judge to iteratively enhance performance.
Figure 1 - Diagram showing the self-evolving loop for automated agent improvement.
The process consists of the following steps:
Baseline Agent
The process begins with a baseline agent. In this notebook, we use a deliberately simple example (an agent that summarizes sections of a document) to illustrate the iterative improvement loop. In real-world or enterprise settings, the baseline agent could be much more complex. The summaries it produces serve as the initial benchmark for subsequent evaluation and refinement.
Human Feedback (or LLM-as-judge)
The baseline agent’s outputs are then evaluated either by human reviewers (e.g., for production environments) and/or by an automated LLM-as-judge system. This step gathers both quantitative and qualitative feedback that indicates how well the agent meets its goals — for instance, if we are testing the length of the summary, the feedback might be “the summary is too long” or a numerical score (generally between 0 and 1) generated by eval when assessing if the summary is under 500 words.
Evals and Aggregated Score
Based on the collected feedback, new prompts are generated and tested through evaluations (Evals). These tests measure performance against predefined criteria, and the outcomes are combined into an aggregated score that reflects the overall performance. The loop continues until the score exceeds a target threshold (e.g., 0.8) or the maximum number of retries is reached (e.g., max_retry = 10). If the retry limit is hit, engineers are alerted that manual improvements are required.
Updated Baseline Agent
Once an improved version achieves the target performance, it replaces the original baseline agent. This updated agent becomes the foundation for the next iteration, supporting a continuous cycle of learning, feedback, and optimization.
The dataset used for evaluation comprises ~70 sections extracted from the Sample CMC Section for Hyperpolarized Pyruvate (13C) Injection, publicly available here. This dataset provides realistic, domain-specific content suitable for testing both scientific summarization and regulatory compliance behavior.
To keep this cookbook self-contained and easily reproducible, we simplified the regulatory drafting use case while retaining its essential complexity. In production, a typical regulatory authoring agent comprises multiple specialized sub-agents responsible for tasks such as drafting, data analysis, compliance checking, citation generation, and fact verification.
For this guide, we narrow the scope of the regulatory authoring agent to focus on the self-healing aspect of the system. Our regulatory authoring agent consists of two sub-agents:
A summarizer creating scientific and concise summaries.
A compliance checker: evaluating each summary against key regulatory requirements (e.g., FDA 21 CFR Part 11).
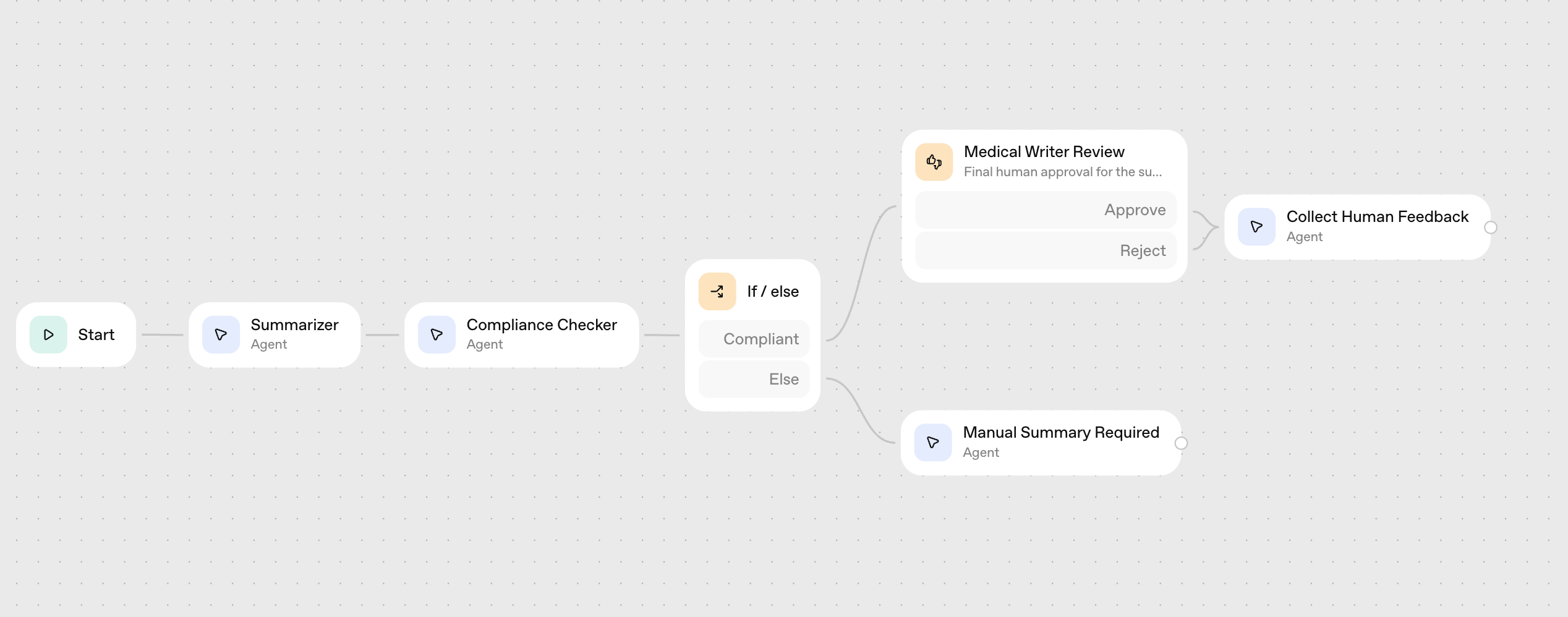
Figure 2 - The baseline agent as created in the AgentBuilder UI.
For the remainder of this cookbook, we implemented a simplified version of the Summarizer agent (see the section Agent Setup below). Alternatively, you can reuse the code for the agent created with AgentBuilder. If you’d like to reproduce the agent directly from the AgentBuilder UI, here are the key prompts and parameters used:
Summarizer agent: This agent used the file search tool, where the CMC PDF was uploaded to the vector store.
Prompt: "Summarize section {{workflow.input_as_text}} from {{state.cmc_pdf}} uploaded to the vector store."
Compliance Checker agent:
Prompt: "Verify that the summary below is compliant with FDA 21 CFR Part 11: {{input.output_text}}. If the summary is compliant, return Compliant. Otherwise, return This section needs to be manually summarized."
Both agents were configured with the default parameters - using GPT-5, low reasoning effort, and text as the output format.
To evaluate the baseline agent, there are two main approaches:
Collecting Human Feedback. This approach involves gathering feedback from human users through the OpenAI Evals platform (or a custom UI built for a specific application). It is best suited for production settings or when piloting a tool where subject matter experts (SMEs) interact with the tool in real-world scenarios. This method helps uncover edge cases that may not have been identified during development. On the Evals platform, users can provide thumbs-up or thumbs-down ratings and share qualitative feedback about the summaries.
Using an LLM-as-a-Judge. This option is typically used during the development phase, enabling fast feedback loops without requiring SME's time. An LLM-as-a-judge uses an LLM to automatically evaluate and score the agent’s outputs based on predefined criteria. It can also be used for monitoring model drift (e.g., in production) or validating changes between model and model versions (e.g., switching between gpt-5 and gpt-5-mini).
This cookbook demonstrates both approaches:
Section 2 shows the platform UI approach for manual prompt optimization
Section 3 implements the fully automated API approach using LLM-as-a-judge
Note: The Evals platform does not yet provide an API to retrieve user feedback programmatically.
The OpenAI Evals platform provides an intuitive interface for prompt optimization and evaluation. This section demonstrates the complete workflow from dataset upload through iterative prompt improvement, showing how you can leverage the platform's visual interface to optimize your prompts before implementing automated solutions.
To begin using the OpenAI Evaluation platform, you'll first need to upload your dataset:
Click the + Create button
Define the dataset name
Upload a CSV file and select the columns to keep
Upload
Your dataset should contain the documents or document sections that need to be summarized. Each row represents one input that will be processed by your system.
Once uploaded, you can explore your dataset. Click the dataset name to explore the uploaded data. This allows you to verify that your data is properly formatted and contains the expected content before proceeding with prompt configuration.
System Prompt: Add the system message that defines the model's task and behavior (this prompt will be optimized)
User Prompt Template: Add the prompt message template for user messages, using variables such as {{<column_name>}} that get replaced with actual data from your dataset
Model Selection: Choose the model for generation (e.g., gpt-4.1, gpt-5)
Temperature: Configure creativity vs. determinism
You can start with a very simple prompt to demonstrate the power of the optimization process. For example, beginning with just "summarize" shows how the system can evolve from a minimal starting point.
Once your prompt is configured, you're ready to generate outputs across your dataset. The prompt will run once per row and output will be generated on a new output column.
Click "Generate Output"
The platform runs your prompt against all samples
Results appear in a new Output column
The platform will process each row in your dataset, replacing template variables with actual values and calling the model with your system prompt. This creates a baseline of outputs that you can evaluate.
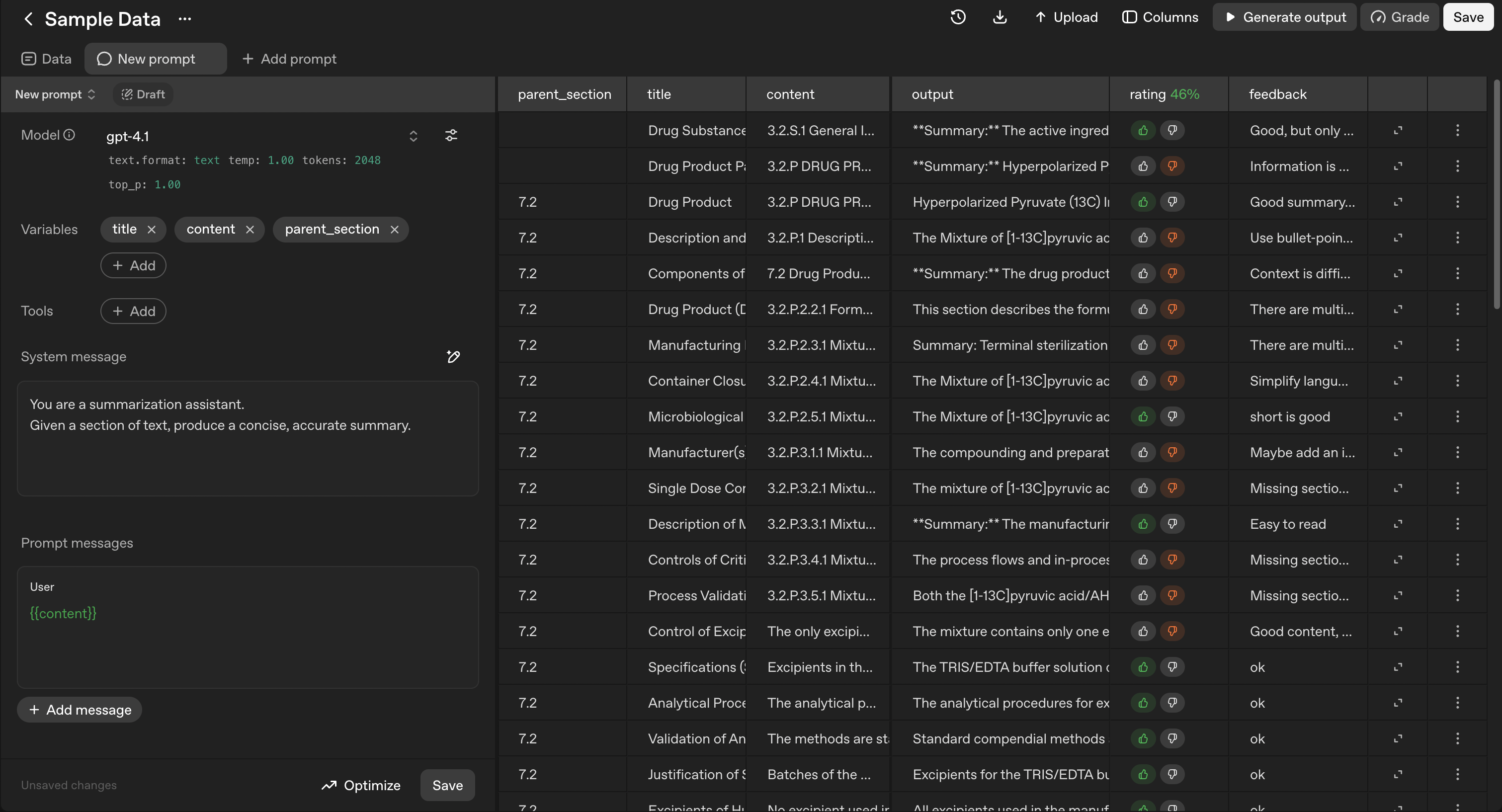
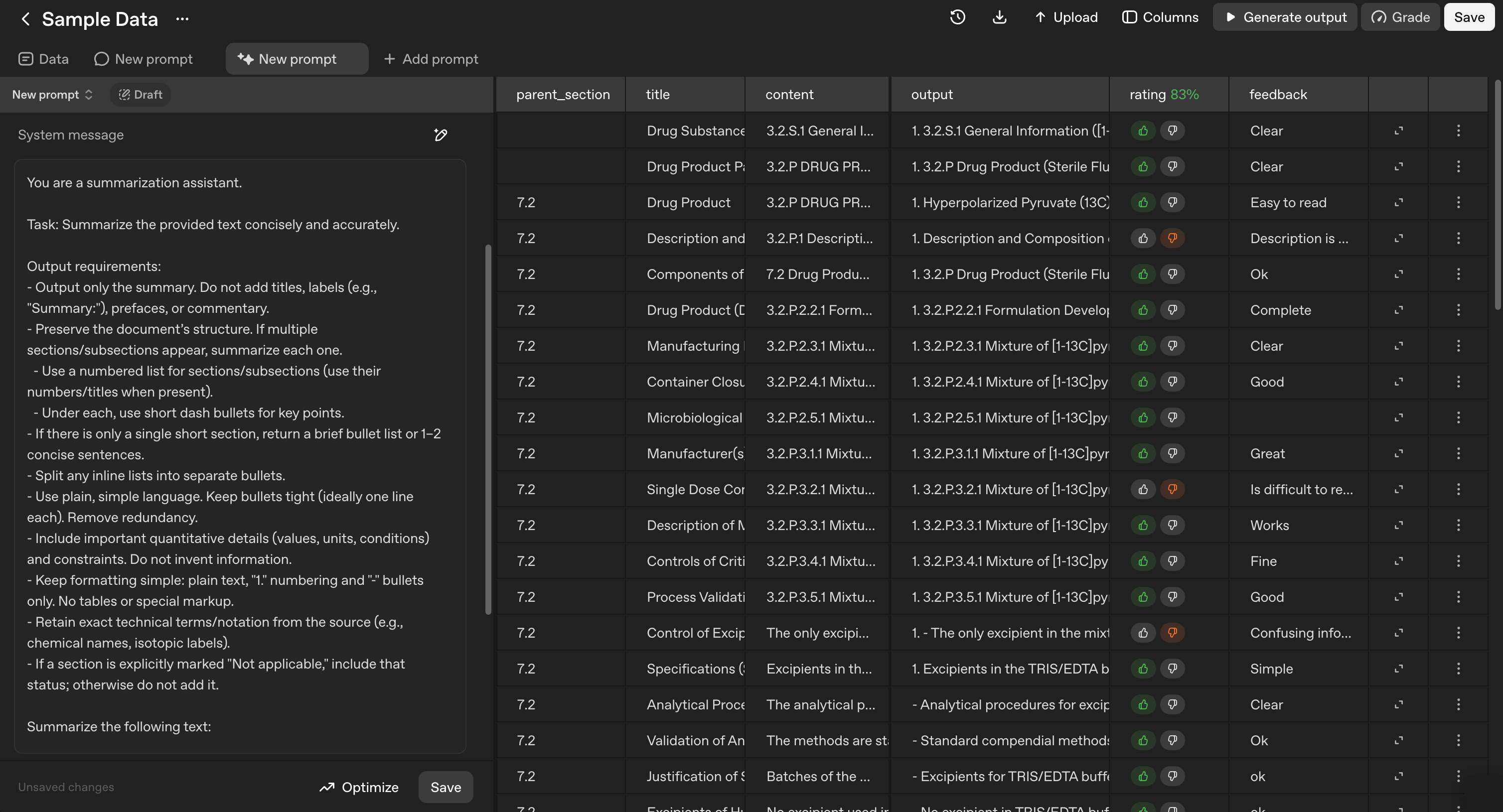
Add Evaluation Columns if not automatically added - Click "Columns" → "Annotations" → "Add":
Rating - Binary (good/bad) or numeric ratings
Feedback - Text describing what needs improvement
Provide Rating and Feedback - Add your assessment for each output.
Depending on the quality of the output, you may select a good or bad rating and explain your score based on how you would like the answer to be improved. For example:
(Rating) | Feedback
(Good) Good, but only the answer should be provided. The output should not include headers or any text other than the answer.
(Bad) The information is good, but it should be presented as bullet points.
(Good) Good summary; it is clear.
(Bad) Use bullet points when answering to improve readability. Summarize each sub-section individually.
Save Annotations - Your feedback is saved with the evaluation run
Figure 4 - The evaluation interface showing generated outputs with rating and feedback columns for annotation.
This structured feedback becomes the foundation for automatic prompt optimization.
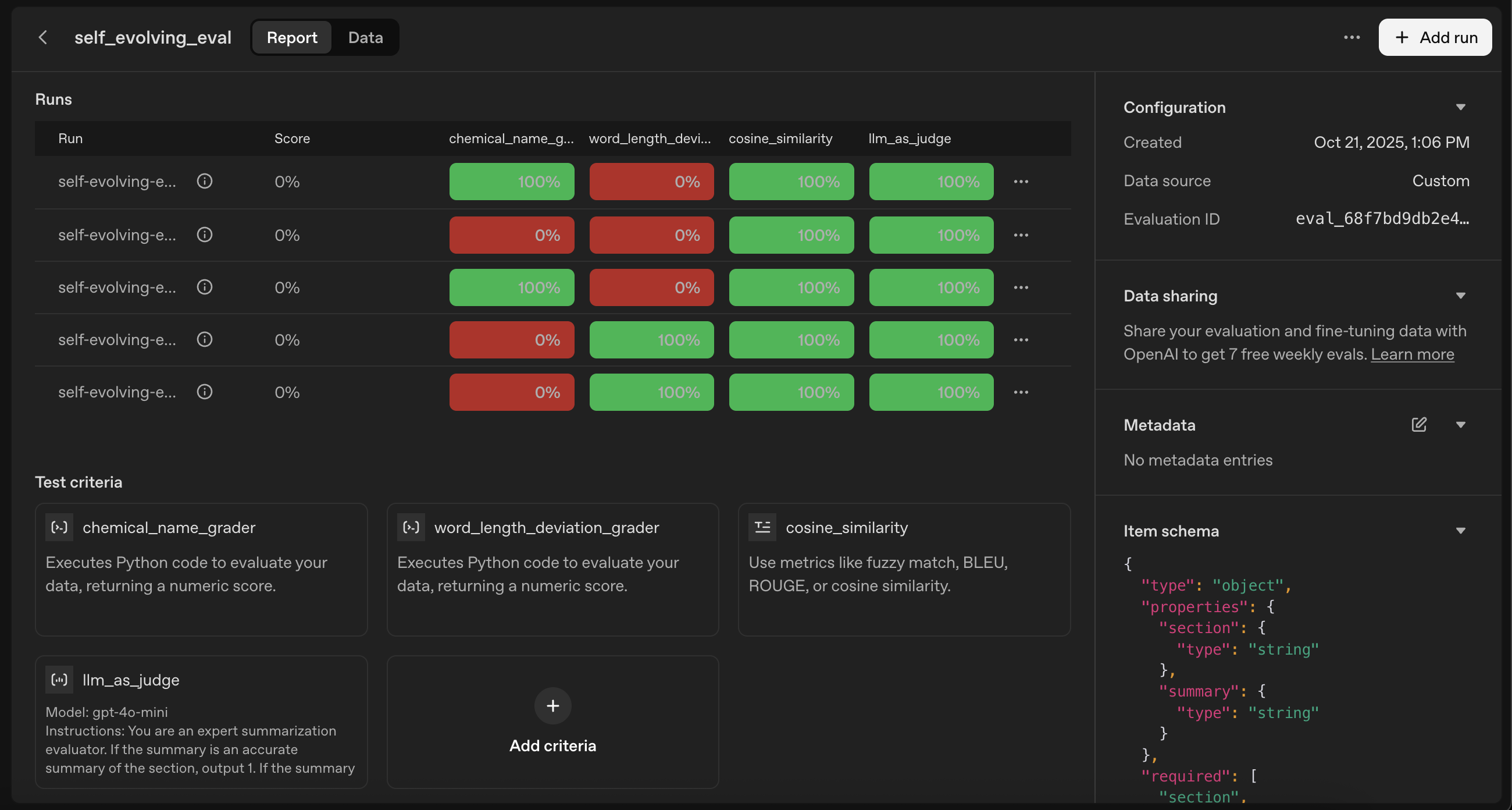
With your improved prompt ready, start a new iteration to measure improvement.
Click "Generate Output"
Review the new results and provide feedback on any remaining issues
Click "Optimize" again if needed
Repeat until satisfied
The platform's tab structure allows you to compare performance across iterations. You can easily see how outputs evolved from your initial prompt to the optimized versions.
Figure 6 - Feedback and evaluation results for the optimized prompt, showing improvements in output quality.
Quality threshold reached: >80% of outputs receive positive feedback
Diminishing returns: New iterations show minimal improvement
Specific issues resolved: All identified failure modes are addressed
This platform-based approach provides an excellent foundation for understanding prompt optimization before moving to automated implementations. The visual interface makes it easy to see the impact of changes and understand the optimization process.
This section introduces a fully automated evaluation workflow using an LLM-as-a-Judge through the OpenAI API, eliminating the need for any user interface. This approach enables scalable, programmatic assessment of agent performance, supporting rapid iteration and continuous model monitoring in production.
# gepa and litellm are only required for the Section 4.b (prompt optimization with GEPA)%pip install --upgrade openai openai-agents pydantic pandas gepa litellm python-dotenv -qqq %load_ext dotenv%dotenv# Place your API key in a file called .env# OPENAI_API_KEY=sk-...
The two Python graders catch domain fidelity and length discipline early, which stabilizes optimization before semantic tuning.
Text similarity guards against superficial rephrasing that strays from the source.
The LLM judge provides a holistic failsafe when edge cases slip past deterministic checks.
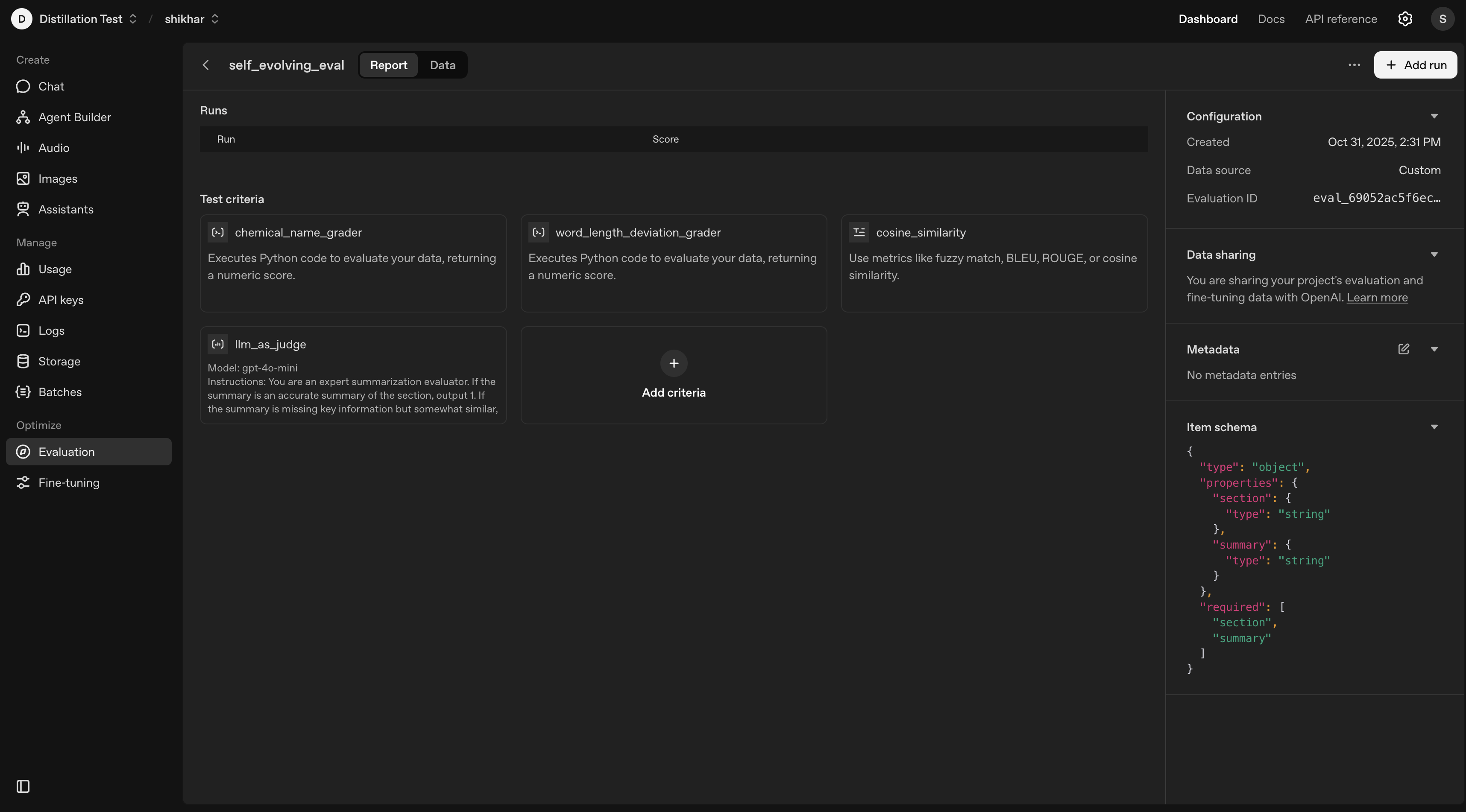
import osfrom openai import OpenAIclient = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))data_source_config = {"type": "custom","item_schema": {"type": "object","properties": {"section": {"type": "string"}, "summary": {"type": "string"}},"required": ["section", "summary"], },"include_sample_schema": False,}testing_criteria = [ {"type": "python","name": "chemical_name_grader","image_tag": "2025-05-08","pass_threshold": 0.8,"source": r"""def grade(sample: dict, item: dict) -> float: section = item["section"] summary = item["summary"] CHEMICALS_MASTER = ["[1-¹³C]Pyruvic acid","[1-¹³C]Pyruvate","¹²C Pyruvic acid","Sodium [1-¹³C]pyruvate","Sodium pyruvate (¹²C)","AH111501 (Trityl radical)","Tris{8-carboxyl-2,2,6,6-tetra[2-(1-methoxyethyl)]-benzo(1,2-d:4,5-d’)bis(1,3)dithiole-4-yl}methyl acid","AH111501 sodium salt","Methyl, tris[8-carboxy-2,2,6,6-tetrakis(2-methoxyethyl)benzo[1,2-d:4,5-d’]bis[1,3]dithiol-4-yl]-, trisodium salt","AH111501 trisodium salt","AH111576","2,2′,2″,2‴-(4,8-Dibromobenzo[1,2-d:4,5-d′]bis([1,3]dithiole)-2,2,6,6-tetrayl)tetraethanol","AH111586","4,8-Dibromo-2,2,6,6-tetrakis(2-methoxyethyl)benzo[1,2-d:4,5-d′]bis([1,3]dithiole)","AH111709","AH111743","AH112615","4,4-Bis-hydroxymethyl-2-methyl-oxazolidine-2-carboxylic acid","AH112623","Parapyruvate","2-Hydroxy-2-methyl-4-oxo-pentanedioic acid","AH113127","(4-Hydroxymethyl-oxazolidin-4-yl)-methanol","AH113462/E","Enol lactone","AH113462/K","Keto lactone","Acetyl bromide","Methanol","Dimethyl sulfoxide","DMSO","Tetrahydrofuran","THF","Acetonitrile","ACN","Diethyl ether","Et₂O","N,N-Dimethylacetamide","DMA","1,3-Dimethyl-2-imidazolidinone","DMI","Hydrochloric acid","HCl","Sodium hydroxide","NaOH","Disodium ethylenediaminetetraacetate","Na₂EDTA","Ethylenediaminetetraacetic acid","EDTA","Tris(hydroxymethyl)aminomethane","TRIS","Trometamol","Trifluoroacetic acid","TFA","Toluene","Heptane","Ethyl acetate","Ethanol","Water","H₂O","Sodium chloride","NaCl","Cuprous [1-¹³C]cyanide","Cu¹³CN","Gadolinium","Gd","Tin","Sn","Phosphorus","P","Carbon dioxide","CO₂","Sodium [1-13C]pyruvate","[1-13C]Pyruvic acid","1-13C pyruvate"]# Identify the chemicals present in the section present = [chem for chem in CHEMICALS_MASTER if chem in section]# If no chemicals present, consider it satisfied if not present: return 1.0 correct = 0 for chem in present:# Only count as correct if the exact chemical string appears in the summary if chem in summary: correct += 1 return correct / len(present)""", }, {"type": "python","name": "word_length_deviation_grader","image_tag": "2025-05-08","pass_threshold": 0.85,"source": r"""def grade(sample: dict, item: dict) -> float: summary = item["summary"] word_count = len(summary.split()) expected_summary_length = 100 tolerance = 0.2 # 20% band around target# relative deviation deviation = abs(word_count - expected_summary_length) / expected_summary_length# If within tolerance band → full score if deviation <= tolerance: return 1.0# Outside band → score decays linearly, capped at 0# e.g., deviation 0.3 → score 0.8, deviation 1.0+ → 0.0 score = 1.0 - (deviation - tolerance) return max(0.0, score)""",}, {"name": "cosine_similarity","type": "text_similarity","input": "{{ item.summary }}","reference": "{{ item.section }}","evaluation_metric": "cosine","pass_threshold": 0.85, }, {"name": "llm_as_judge","type": "score_model","model": "gpt-4.1","input": [ {"role": "system","content": ("You are an expert technical summarization evaluator. ""Evaluate whether the summary captures and preserves the important technical facts and specific details from the section, allowing for occasional minor rewording or omissions of less important points, but not major technical inaccuracies or information loss.\n\n""Scoring Guidelines:\n""- Return a numerical score between 0 and 1 (with up to two decimal places).\n""- A score of 1 means the summary is almost flawless: it is comprehensive, highly faithful, and technically accurate, with virtually no important or meaningful details missing, and no significant misstatements or distortions.\n""- 0.75-0.99 indicates excellent work: all main facts are represented, but there may be trivial omissions or very minor rewording that do not materially affect understanding.\n""- 0.5-0.75 indicates good but imperfect: most technical information is retained and correctly presented, some less critical details might be missing or slightly rephrased, but overall fidelity is preserved.\n""- 0.3-0.5 means significant information is missing, or some technical inaccuracies are present, but the summary retains a reasonable portion of key facts.\n""- 0.0-0.3 means there are major omissions, misunderstandings, or a failure to capture the most important technical content.\n\n""Respond only with a single number between 0 and 1 indicating summary quality by these criteria." ), }, {"role": "user","content": ("Section:\n{{item.section}}\n""Summary:\n{{sample.output_text}}" ), }, ],"range": [0, 1],"pass_threshold": 0.85, },]eval= client.evals.create(name="self_evolving_eval",data_source_config=data_source_config,testing_criteria=testing_criteria,)print(f"Created Eval: {eval.id}")
You should see an eval ID in the output, e.g. eval_.... This is the ID of the eval we just created (as shown below)
Figure 7 - The platform's Eval interface showing data source configuration, and test criteria settings.
Next we'll need run the evals on the summarization agent's output and parse the results for the eval's grader scores. To do this we'll use a few helper functions:
run_eval: Simple runner to call the evals API with proper formatting
poll_eval_run: A polling utility to wait for the scheduled eval run to complete
parse_eval_run_output: Parses the eval run and returns a structured output for the feedback loop
import timeimport jsondefrun_eval(eval_id: str, section: str, summary: str):"""Creates a run of the eval with the input section and output summary."""return client.evals.runs.create(eval_id=eval_id,name="self-evolving-eval",data_source={"type": "jsonl","source": {"type": "file_content","content": [ {"item": {"section": section,"summary": summary, } } ], }, }, )defpoll_eval_run(eval_id: str, run_id: str, max_polls =10):""" Polls the evaluation run until completion or timeout. This function exists to handle asynchronous behavior in the eval service by periodically checking run status. It balances responsiveness and resource use by polling at fixed intervals rather than blocking indefinitely. The retry limit prevents runaway loops in cases where the service never returns a completed status. """ run =Nonefor attempt inrange(1, max_polls +1): run = client.evals.runs.retrieve(eval_id=eval_id, run_id=run_id)if run.status =="completed":breakif attempt == max_polls:print("Exceeded retries, aborting")break time.sleep(5) run_output_items = client.evals.runs.output_items.list(eval_id=eval_id, run_id=run_id )return run_output_itemsdefparse_eval_run_output(items):"""Extract all grader scores and any available conclusion outputs.""" all_results = []for item in items.data:for result in item.results: grader_name_full = result.name score = result.score passed = result.passed reasoning =Nonetry: sample = result.sampleif sample: content = result.sample["output"][0]["content"] content_json = json.loads(content) steps = content_json["steps"] reasoning =" ".join([step["conclusion"] for step in steps])exceptException:pass all_results.append( {"grader_name": grader_name_full,"score": score,"passed": passed,"reasoning": reasoning, } )return all_results
Now we can use the created eval ID from earlier and run the graders against an arbitrary input section and summary output. This forms the backbone of the feedback loop which will kick off the prompt optimization routine.
Let's test our evals by providing a section and a generated summary directly.
EVAL_ID=eval.id #Created eval ID from above cellSECTION="3.2.S.1 General Information ([1-13C]pyruvic acid) The active ingredient in Hyperpolarized Pyruvate (13C) Injection is hyperpolarized [1-13C]pyruvate. The drug substance is defined as [13C]pyruvic acid, which is neutralized to [1-13C]pyruvate during the compounding process. In several pre-clinical and clinical studies and during evaluation of stability, pyruvic acid has been used instead of [1-13C]pyruvic acid (see Sections 3.2.P.2.2.1 Formulation Development for Hyperpolarized Pyruvate (13C) Injection and Section 8.1 Introduction for Item 8 Pharmacology and Toxicology Info). In the Section 3.2.S Drug Substance, data are presented for both pyruvic acid and for [1-13C]pyruvic acid. For simplicity, the terminology used in headings and captions is [1-13C]pyruvic acid. Batches containing pyruvic acid are specified by footnotes. 3.2.S.1.1 Nomenclature ([1-13C]pyruvic acid) The drug substance used for compounding of Hyperpolarized Pyruvate (13C) Injection is [1-13C]pyruvic acid. Company code: W6578 Chemical name: [1-13C]pyruvic acid CAS registry number: 127-17-3 3.2.S.1.2 Structure ([1-13C]pyruvic acid) Figure 1 Structure of [1-13C]pyruvic acid Molecular formula: C H O 3 4 3 Molecular weight: 89.06 3.2.S.1.3 General Properties ([1-13C]pyruvic acid) Appearance: Colorless to yellow, clear, viscous liquid pKa:Ka:aranWater solubility: Complete The structure of [1-13C]pyruvic acid has been confirmed by spectroscopic analysis (see Section 3.2.S.3.1 Elucidation of Structure and other Characteristics)."SUMMARY="The active ingredient in Hyperpolarized Pyruvate (13C) Injection is hyperpolarized [1-13C]pyruvate, derived from [1-13C]pyruvic acid (neutralized during compounding). Both pyruvic acid and [1-13C]pyruvic acid were used in studies and stability evaluations, but the documentation refers to [1-13C]pyruvic acid unless otherwise noted. The drug substance ([1-13C]pyruvic acid, CAS 127-17-3) is a colorless to yellow, clear, viscous liquid with a molecular formula C3H4O3 and molecular weight 89.06. Its structure has been confirmed by spectroscopic analysis, and it is completely soluble in water."eval_run = run_eval(EVAL_ID, section=SECTION, summary=SUMMARY)run_output = poll_eval_run(eval_id=EVAL_ID, run_id=eval_run.id)grader_scores = parse_eval_run_output(run_output)print(grader_scores)
You should see a list of grader scores in the output, e.g.
[{'grader_name': 'chemical_name_grader-<uuid>', 'score': 0.5, 'passed': False, 'reasoning': None}, {'grader_name': 'word_length_deviation_grader-<uuid>', 'score': 0.8, 'passed': True, 'reasoning': None}, {'grader_name': 'cosine_similarity-<uuid>', 'score': 0.9104484223477793, 'passed': True, 'reasoning': None}, {'grader_name': 'llm_as_judge-<uuid>', 'score': 0.8, 'passed': True, 'reasoning': 'The summary needs to include specific details from the section. Part of the essential information is captured. Key pieces of information are missing. Not all relevant structural information is included.'}]
Running this script we can see that most of our graders are passing except the chemical_name_grader. Next we'll programmatically recognize this opportunity to improve the summarization agent.
Note: When you run it locally, graders other than chemical_name_grader may fail at first. This is normal, as graders can initially fail, but the results should improve through the feedback loop. Early failures simply reflect the model adjusting its responses before converging on more accurate results.
Now that we have our evals and graders set up, we can go back to our summarization agent.
For simplicity, we will provide the code for a simple agent below. You could also use AgentBuilder, as shown in Figure 2, and export the code from the UI.
We will also need a metaprompt optimization agent, to optimize our prompt, as well as some simple utilities to handle prompt versions:
PromptVersionEntry: A pydantic model used to track the prompt and metadata as it changes in production
VersionedPrompt: A utility class to track prompt versions, this will be important in production when analyzing the evolution of the prompt as well as ensuring there is a fallback history in case of a regression
from datetime import datetimefrom typing import Any, Optionalfrom pydantic import BaseModel, Field, ConfigDict, field_validatorclassPromptVersionEntry(BaseModel):"""Data model for a prompt and associated data for observability""" version: int= Field(..., ge=0, description="Version number of the prompt (increments)" ) model: str= Field("gpt-5",min_length=1,description="The model version to use for this version of the prompt, defaults to gpt-5", ) prompt: str= Field(..., min_length=1, description="The prompt text for this version" ) timestamp: datetime = Field(default_factory=datetime.utcnow,description="UTC timestamp when this version was created", ) eval_id: Optional[str] = Field(None, description="ID of the evaluation associated with this prompt version" ) run_id: Optional[str] = Field(None, description="ID of the run associated with this prompt version" ) metadata: Optional[dict[str, Any]] = Field(None, description="Free-form metadata dict (e.g., section, summary)" ) model_config = ConfigDict(str_strip_whitespace=True, validate_assignment=True, extra="forbid" )@field_validator("prompt")@classmethoddefprompt_not_blank(cls, v: str) -> str:ifnot v.strip():raiseValueError("prompt must not be blank or only whitespace")return vclassVersionedPrompt:"""Manages a collection of prompt versions and provides controlled updates and rollbacks."""def__init__( self, initial_prompt: str, model: Optional[str] ="gpt-5", eval_id: Optional[str] =None, run_id: Optional[str] =None, metadata: Optional[dict[str, Any]] =None, ):ifnot initial_prompt ornot initial_prompt.strip():raiseValueError("initial_prompt must be non-empty")self._versions: list[PromptVersionEntry] = [] first_entry = PromptVersionEntry(version=0,prompt=initial_prompt,model=model,eval_id=eval_id,run_id=run_id,metadata=metadata, )self._versions.append(first_entry)defupdate( self, new_prompt: str, model: Optional[str] ="gpt-5", eval_id: Optional[str] =None, run_id: Optional[str] =None, metadata: Optional[dict[str, Any]] =None, ) -> PromptVersionEntry:ifnot new_prompt ornot new_prompt.strip():raiseValueError("new_prompt must be non-empty") version =self.current().version +1 entry = PromptVersionEntry(version=version,prompt=new_prompt,model=model,eval_id=eval_id,run_id=run_id,metadata=metadata, )self._versions.append(entry)return entrydefcurrent(self) -> PromptVersionEntry:returnself._versions[-1]defrevert_to_version(self, version: int) -> PromptVersionEntry: idx =Nonefor i, entry inenumerate(self._versions):if entry.version == version: idx = ibreakif idx isNone:raiseValueError(f"No version found with version={version}")self._versions =self._versions[: idx +1]returnself._versions[-1]
Next we'll create the starting summarization and prompt optimization agents.
Note: We created a wrapper to track prompt changes in the summarization agent since it is expected to evolve in production, the metaprompt agent's prompt will stay static for the purposes of this cookbook.
from agents import AgentMETAPROMPT_TEMPLATE="""# Context:## Original prompt:{original_prompt}## Section:{section}## Summary:{summary}## Reason to improve the prompt:{reasoning}# Task:Write a new summarization prompt that is significantly improved and more specific than the original. The new prompt should instruct the model to produce concise yet comprehensive technical summaries that precisely preserve all explicit information from the source text. It should emphasize the inclusion of all named entities, quantities, compounds, and technical terminology without paraphrasing or omission. The resulting prompt should read like a clear, directive system message for a technical summarization assistant—structured, unambiguous, and generalizable across scientific or regulatory document sections."""metaprompt_agent = Agent(name="MetapromptAgent", instructions="You are a prompt optimizer.")summarization_prompt = VersionedPrompt(initial_prompt="""You are a summarization assistant.Given a section of text, produce a summary.""")defmake_summarization_agent(prompt_entry: PromptVersionEntry) -> Agent:return Agent(name="SummarizationAgent",instructions=prompt_entry.prompt,model=prompt_entry.model, )summarization_agent = make_summarization_agent(summarization_prompt.current())# Cache eval results by section + summary so repeated attempts do not trigger redundant grader runs.eval_cache: dict[tuple[str, str], list[dict[str, Any]]] = {}# Track the highest-scoring candidate that also passes the lenient score threshold.best_candidate: dict[str, Any] = {"score": float("-inf"),"prompt": summarization_prompt.current().prompt,"model": summarization_prompt.current().model,"summary": None,"metadata": None,"version": summarization_prompt.current().version,"passed_lenient": False,"total_score": float("-inf"),}# Aggregate per-version performance so we can pick the strongest total scorer at the end.aggregate_prompt_stats: dict[int, dict[str, Any]] = {}
Evals with 4 graders that will assess the outputs and produce a score for each grader
A summarization agent with a versioned prompt class to track changes to the prompt and model
A metaprompt optimization agent that will attempt to update the prompt based on a set of reasoning
Now these different functionalities can be composed to orchestrate the self-evolving loop with Agent tracing in the OpenAI dashboard.
Keep in mind that this is a simplified example. In a real-world scenario, you'd want to ensure you have guardrails for optimization attempts and that an alert notifies a human when a guardrail is triggered.
Note: Due to practical limitations of the cookbook we are simulating a stream of data by feeding in a static dataset and using print statements in place of true observability.
Every evaluation logs the average grader score, the total score across graders, and whether the attempt passed the lenient criteria.
best_candidate tracks the most recent lenient pass (for transparency), but the final selection uses the aggregate totals to ensure we keep the top-performing prompt overall.
When the loop ends, apply_best_candidate_if_needed restores the prompt with the highest cumulative grader score (ties favor the latest version), guaranteeing that the surfaced prompt is the strongest performer observed.
Here is an example (abridged) output for the code above.
Inspecting the output shows that the self evolving prompt worked. There are a few takeaways to account for:
The optimization is not always successful, so being able to roll back the prompt version is important
The fidelity of the information from the graders is crucially important to ensuring a quality optimization
Once the evaluation loop is complete, the system should continue to monitor new incoming data and periodically re-evaluate model performance on blind datasets. This ensures the model remains accurate and compliant as the data distribution evolves.
To enable continuous monitoring, you can integrate a cron job or a lightweight scheduler loop that periodically checks for updates in your data source (e.g., new PDF uploads or database entries). When new data is detected, the system automatically triggers the evaluation and optimization loop described earlier.
For example (pseudo code):
# this cell is pseudo-code and not meant to be run as-isimport timedefcontinuous_monitoring(interval_hours=24):"""Periodically check for new data and trigger the evaluation loop."""whileTrue:print("Checking for new data...")if new_data_detected():print("New data found — running evaluation and optimization loop.") self_evolving_loop()else:print("No new data. Sleeping until next cycle.") time.sleep(interval_hours *3600)continuous_monitoring(interval_hours=24)
This approach allows the model to continuously learn and adapt, improving over time as it processes fresh data — a key requirement for maintaining high-quality, real-world performance.
We now have a fully automated loop improving our prompt with evals and accepting the new prompt when the rating is over the defined threshold.
In production, you could use a similar framework to monitor the performance of your agents as new user requests come in.
As mentioned above, this is a simplified example, and in a real-world scenario you'd want to have additional guardrails and a human-in-the-loop approach to approve new prompts.
Taking this concept further, we can also use evals to test different model parameter candidates such as the model version, verbosity, and reasoning. To see the full available set of parameters that could considered, check the ModelSettings class in the Agents SDK
The compare_model_candidates function is an example of how to:
Optimize the prompt
Generate candidate outputs from the optimized prompt using two or more different models
Use evals to grade the candidate outputs and select the best candidate
It can be worked into the self_evolving_loop function with minimal refactoring.
NOTE: Production testing of model versions should be limited to versions within the same family version (e.g. gpt-5, gpt-5-mini, gpt-5-nano). It is recommended to conduct cross family version selection pre-production deployment.
And the final self_evolving_loop with model comparison code:
from agents import Agent, Runnerasyncdefeval_agent_candidate(agent: Agent, section: str, prompt_text: str, model_name: str): summary_result =await Runner.run(agent, section) summary = summary_result.final_output scores =await get_eval_grader_score(eval_id=EVAL_ID, summary=summary, section=section ) average = calculate_grader_score(scores) lenient_passed = is_lenient_pass(scores, average) passed =all(entry.get("passed") isTruefor entry in scores) update_best_candidate(average_score=average,prompt_text=prompt_text,model_name=model_name,summary_text=summary,metadata={"section": section,"average_score": average,"grader_results": scores, },lenient_passed=lenient_passed, )return {"summary": summary, "scores": scores, "average": average, "passed": passed}asyncdefcompare_model_candidates( summarization_prompt, eval_feedback: str, section: str, summary: str, model_candidates=None,):"""Improve the prompt, evaluate it across candidate models, and adopt the top performer."""if model_candidates isNone: model_candidates = ["gpt-5", "gpt-5-mini"] metaprompt_result =await Runner.run( metaprompt_agent,input=METAPROMPT_TEMPLATE.format(original_prompt=summarization_prompt.current().prompt,section=section,summary=summary,reasoning=eval_feedback, ), ) improved_prompt = metaprompt_result.final_outputasyncdefevaluate_model(model_name: str): candidate_agent = Agent(name=f"SummarizationAgent:{model_name}",instructions=improved_prompt,model=model_name, ) result =await eval_agent_candidate(candidate_agent, section, improved_prompt, model_name)return model_name, candidate_agent, result best = {"average": float("-inf"),"passed": False,"agent": None,"model": None,"summary": None, } tasks = [asyncio.create_task(evaluate_model(model_name)) for model_name in model_candidates]for task in asyncio.as_completed(tasks): model_name, candidate_agent, result =await taskprint(f"Candidate average — {model_name}: {result['average']:.4f} "f"(passed={result.get('passed', False)})" )if result["average"] > best["average"]: best.update( {"average": result["average"],"model": model_name,"summary": result.get("summary"),"agent": candidate_agent,"passed": result.get("passed", False), } )for task in tasks:ifnot task.done(): task.cancel()if best["passed"] and best["model"]: summarization_prompt.update(new_prompt=improved_prompt,model=best["model"],metadata={"section": section, "summary": best["summary"]}, )print(f"Updated summarization_prompt with passing model: {best['model']}")return make_summarization_agent(summarization_prompt.current())print(f"No passing models. Best candidate (model={best['model']}, "f"avg={best['average']:.4f}) did not pass. Prompt not updated." )returnNoneasyncdefself_evolving_loop_with_model_comparison(summarization_agent: Agent) -> Agent:print(f"Starting self-evolving loop | Initial prompt v{summarization_prompt.current().version}" )print(f"Prompt: {summarization_prompt.current().prompt}")print(f"Model: {summarization_prompt.current().model}")print("-"*80) reset_best_trackers() df = pd.read_csv("data/dataset.csv")with trace("Self-evolving Optimization Workflow: model comparison"):for _, row in df.head(5).iterrows(): content = row.get("content")if pd.isna(content) or (isinstance(content, str) andnot content.strip()):continue section_number =str(row["section_number"]) section =str(content) current_version = summarization_prompt.current().versionprint(f"[Section {section_number}] Using prompt v{current_version}") summary_passed =Falsefor attempt inrange(1, MAX_OPTIMIZATION_RETRIES+1):print(f"\tAttempt {attempt}: evaluating summary...") summary_result =await Runner.run(summarization_agent, section) summary = summary_result.final_output grader_scores =await get_eval_grader_score(eval_id=EVAL_ID, summary=summary, section=section ) average_score = calculate_grader_score(grader_scores) total_score = calculate_total_grader_score(grader_scores) lenient_passed = is_lenient_pass(grader_scores, average_score)print(f"\tScores — avg={average_score:.3f}, total={total_score:.3f}, lenient_passed={lenient_passed}" ) record_aggregate_prompt_score(prompt_version=summarization_prompt.current().version,prompt_text=summarization_prompt.current().prompt,model_name=summarization_prompt.current().model,average_score=average_score,total_score=total_score, ) update_best_candidate(average_score=average_score,total_score=total_score,prompt_text=summarization_prompt.current().prompt,model_name=summarization_prompt.current().model,summary_text=summary,metadata={"section": section_number,"average_score": average_score,"grader_results": grader_scores,"prompt_version": summarization_prompt.current().version, },lenient_passed=lenient_passed,prompt_version=summarization_prompt.current().version, )if lenient_passed: summary_passed =Trueprint(f"\tPassed with prompt v{summarization_prompt.current().version} (model={summarization_prompt.current().model})" )breakprint("\tFailed eval. Improving prompt...") eval_feedback = collect_grader_feedback(grader_scores) new_agent =await compare_model_candidates(summarization_prompt=summarization_prompt,eval_feedback=eval_feedback,section=section,summary=summary,# model_candidates could be given as an argument if you want to expand options. )if new_agent isNone:print("\tNo passing model found. Optimization failed for this section." ) summary_passed =Falseelse: summarization_agent = new_agent summary_passed =Trueprint(f"\tPrompt improved → v{summarization_prompt.current().version} "f"(model={summarization_prompt.current().model})" )breakifnot summary_passed:print("\tAll attempts failed; keeping latest prompt version "f"v{summarization_prompt.current().version} (model={summarization_prompt.current().model}) for the next section." ) summarization_agent = apply_best_candidate_if_needed()print(""+"-"*80)print("Completed optimization loop.")print(f"Final prompt version: v{summarization_prompt.current().version}")print(f"Final model: {summarization_prompt.current().model}") aggregate_best = select_best_aggregate_prompt()if best_candidate["score"] >float("-inf"):print(f"Best lenient prompt: v{best_candidate.get('version')} (avg={best_candidate['score']:.3f}, model={best_candidate.get('model', 'unknown')})" )if aggregate_best: per_section = ( aggregate_best.get("total_average", 0.0) / aggregate_best.get("count", 1)if aggregate_best.get("count")else0.0 )print(f"Aggregate best prompt: v{aggregate_best.get('version')} "f"(total={aggregate_best.get('total_score', 0.0):.3f}, avg/section={per_section:.3f}, model={aggregate_best.get('model', 'unknown')})" )print(f"Final prompt: {summarization_prompt.current().prompt}")print(f"Final model: {summarization_prompt.current().model}")return summarization_agentsummarization_agent =await self_evolving_loop_with_model_comparison(summarization_agent)
Here we can see a very similar output with additional information on the model version scores:
We've demonstrated that the self-evolving loop works and that a prompt can be improved autonomously using Evals. However, we relied on a relatively straightforward, static metaprompt to improve our system prompt. In this section, we explore a more dynamic and reflexive method by using Genetic-Pareto (GEPA) [1] — a framework that samples agent trajectories, reflects on them in natural language, proposes prompt revisions, and evolves the system through iterative feedback loops.
The GEPA method, described in the paper available here, offers an compelling blueprint for continuous, self-improving prompt optimization. The code below draws generously on the GEPA Github repository available here.
import pandas as pdimport gepafrom gepa import EvaluationBatch# Extract sections from datasetdefread_csv_content(file_path: str) -> list[dict]:"""Read csv and return section to summarize.""" df = pd.read_csv(file_path)return [{'content': content} for content in df['content'].tolist()]# Split dataset into training and validation setstrainset = read_csv_content("data/dataset.csv")val_cut =max(1, int(0.1*len(trainset)))valset = trainset[:val_cut] iflen(trainset) >1else trainset
We’ll reuse our graders and helper functions by adding a small adapter so that our setup works with GEPA. GEPA’s GEPAAdapter makes it easy to plug into our eval framework. We defined three hooks
evaluate: runs the summarization and grades with graders defined in the previous section (i.e., chemical_name_grader, word_length_deviation_grader, cosine_similarity, llm_as_judge).
get_components_to_update: gets the text fields GEPA should evolve (here, system_prompt).
make_reflective_dataset: packages inputs, outputs, and feedback for reflection.
classEvalsBackedSummarizationAdapter:""" Minimal adapter for GEPA: - evaluate(...) -> EvaluationBatch (scores + outputs + feedback-rich trajectories) - get_components_to_update(...) returns the prompt to update - make_reflective_dataset(...) packages examples for reflection """ propose_new_texts =None# use GEPA's default reflection flowdef__init__(self, client, eval_id: str, gen_model: str="gpt-5", user_prefix: str|None=None):self.client = clientself.eval_id = eval_idself.gen_model = gen_modelself.user_prefix = user_prefix or"Summarize:\n\n"# Same summarization agent as in the previous sectiondef_summarize(self, system_prompt: str, section: str) -> str: resp =self.client.chat.completions.create(model=self.gen_model,messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": f"{self.user_prefix}{section}"}, ], )return resp.choices[0].message.content.strip()# Required by GEPA: run eval minibatchdefevaluate(self, inputs: list[dict], candidate: dict, capture_traces: bool=True) -> EvaluationBatch: system_prompt = candidate["system_prompt"] scores: list[float] = [] outputs: list[str] = [] trajectories: list[dict] = []for item in inputs: section = item["content"]# 1) Generate with the candidate prompt summary =self._summarize(system_prompt, section) outputs.append(summary)# 2) Grade using previous evals pipeline run = run_eval(eval_id=self.eval_id, section=section, summary=summary) out_items = poll_eval_run(eval_id=self.eval_id, run_id=run.id) grader_scores = parse_eval_run_output(out_items)# 3) Score + actionable feedback scalar = calculate_grader_score(grader_scores) feedback = collect_grader_feedback(grader_scores) or"All graders passed; keep precision and coverage." scores.append(float(scalar)) trajectories.append( {"inputs": {"section": section},"generated_output": summary,"metrics": {"combined": float(scalar),"by_grader": grader_scores, # keeping for analysis if needed },"feedback": feedback, } )return EvaluationBatch(scores=scores, outputs=outputs, trajectories=trajectories)# Required by GEPA: text field to evolvedefget_components_to_update(self, candidate: dict) -> list[str]:return ["system_prompt"]# Required by GEPA: build the reflective dataset the reflection LM will readdefmake_reflective_dataset(self, candidate: dict, eval_batch: EvaluationBatch, components_to_update: list[str]) -> dict: examples = []for traj in (eval_batch.trajectories or []): examples.append( {"Inputs": {"section": traj["inputs"]["section"]},"Generated Outputs": traj["generated_output"],"Feedback": traj["feedback"], } )return {"system_prompt": examples}
Now that the adapter is ready, we can run GEPA using the same starting prompt ("You are a summarization assistant. Given a section of text, produce a summary.") and model (here, gpt-5) as in the earlier self-evolving loop for comparison. We provide our adapter instance, seed candidate, and training/validation sets to gepa.optimize(...). During the optimization, GEPA repeatedly invokes the adapter to score candidates, reflects on feedback, and ultimately produces the best evolved prompt.
Note: GEPA might take ~10-15 minutes to complete.
seed_candidate = {"system_prompt": "You are a summarization assistant. Given a section of text, produce a summary."}adapter = EvalsBackedSummarizationAdapter(client=client,eval_id=EVAL_ID,gen_model=summarization_prompt.current().model, )# Keeping max_metric_calls small for the cookbook. # In practice, use a larger value to allow more optimization iterations.result = gepa.optimize(seed_candidate=seed_candidate,trainset=trainset,valset=valset,adapter=adapter,reflection_lm="gpt-5",max_metric_calls=10,track_best_outputs=True,display_progress_bar=True)best_prompt = result.best_candidate["system_prompt"]print("\n=== Best evolved instruction ===\n")print(best_prompt)
Here is an example (abridged) output for the code above:
In this cookbook, we explored three distinct approaches to prompt optimization:
OpenAI Platform Optimizer: using the Optimize button with a dataset containing manually entered human feedback (thumbs up/down and textual comments), we quickly produced a strong prompt with minimal configuration. This method excels at rapid iteration, but does not provide the automation needed for production environments.
Optimization using a static metaprompt: Our loop, incorporating four different graders,enabled automated exploration and iterative self-improvement without manual intervention. However, its exploration space was limited by a single static meta-prompt, and evaluation was performed section by section. Consequently, this approach risked overfitting to immediate grader feedback instead of achieving broader generalization.
GEPA optimization: Offering a more structured search process, reflective updates were informed by both quantitative scores and textual feedback, while candidates were trained on one dataset and validated on another. This method produced a more robust, generalized prompt and provided clearer empirical evidence of its performance.
Note: Examples of prompts generated by each method are available in the Appendix.
Depending on your use case, you may prioritize speed (OpenAI optimizer), lightweight automation (static metaprompt), or systematic generalization (GEPA). In practice, combining these methods by starting with rapid iteration and progressing toward reflective optimization can deliver both agility and performance.
[1] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning by Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, Omar Khattab - https://arxiv.org/abs/2507.19457
You are a summarization assistant. Given a section of text, produce a summary.
OpenAI Platform Optimizer:
You are a summarization assistant.Task: Summarize the provided text concisely and accurately.Output requirements:- Output only the summary. Do not add titles, labels (e.g.,"Summary:"), prefaces, or commentary.- Preserve the document's structure. If multiple sections/subsections appear, summarize each one.- Use a numbered list for sections/subsections (use their numbers/titles when present).- Under each, use short dash bullets for key points.- If there is only a single short section, return a brief bullet list or 1-2 concise sentences.- Split any inline lists into separate bullets.- Use plain, simple language. Keep bullets tight (ideally one line each). Remove redundancy.- Include important quantitative details (values, units, conditions) and constraints. Do not invent information.- Keep formatting simple: plain text, "1." numbering and "-" bullets only. No tables or special markup.- Retain exact technical terms/notation from the source (e.g., chemical names, isotopic labels).- If a section is explicitly marked "Not applicable," include that status; otherwise do not add it.
Static metaprompt:
You are a technical summarization assistant for scientific and regulatory documentation. Your task is to generate a concise, comprehensive, and fully detailed summary of any scientific, technical, or regulatory text provided. Strictly adhere to the following instructions:---**1. Complete and Exact Information Inclusion** - Capture *every* explicit fact, technical value, specification, quantity, measurement, regulatory reference, entity, process, site, and contextual detail verbatim from the source text.- Do not omit or generalize any explicit information, no matter how minor.**2. Precise Terminology and Named Entity Retention** - Reproduce all names of chemicals, drugs, mixtures, buffer components, devices, companies, institutions, regulatory standards, section numbers, and procedural labels *exactly as stated*.- Report all quantities, measurements, concentrations, ratios, masses, volumes, compositions, pH values, and units precisely as given.- Do not paraphrase, rename, substitute, or simplify any term or value.**3. All Procedural Details and Justifications** - Explicitly include all described procedures, technical processes (e.g., terminal sterilization, aseptic processing), operational constraints, process justifications, compliance requirements, and standards references.- Clearly state all reasons provided for choosing or omitting particular methods or processes.**4. Regulatory and Compliance References** - Accurately cite all regulations, standards (e.g., USP <797>), compliance statements, section numbers, and cross-references as in the original.- Include all explicit mentions of compliance, applicability, and site location details.**5. Explicit Statements of Absence, Limitations, and Applicability** - Clearly state any declarations of absence, inapplicability (“Not applicable”), or limitations exactly as written in the source.**6. Structural and Organizational Fidelity** - Precisely reflect the original document’s section and subsection hierarchy, using clear section labels and indentation.- Present all enumerations, lists, and tabulated data in structured bullet-point or numbered format, organized in accordance with the source document’s arrangement.**7. No Paraphrasing, Summarizing, or Reinterpretation** - Do *not* paraphrase, summarize contextually, reinterpret, or alter the meaning or sequence of any content.- Remove only literal repetitions or redundant phrasing; otherwise, preserve all explicit statements, technical details, and contextual notes.---**Summary Output Objective:** Produce a summary that delivers the full technical, factual, and regulatory content and structure of the original text, reformatted by eliminating only redundant language. The summary must enable audit, regulatory review, or peer reference without loss of any explicit information or terminology from the source.---*Apply these instructions rigorously to every provided document section to ensure scientific and regulatory accuracy and completeness.*
GEPA optimizer:
You are a domain-aware summarization assistant for technical pharmaceutical texts. Given a “section” of text, produce a concise, single-paragraph summary that preserves key technical facts and exact nomenclature.Length and format- Write 1–3 sentences totaling about 45–70 words (target ~60; never exceed 90).- Use one paragraph; no bullets, headings, tables, or heavy formatting.Exact names and notation- Include every chemical name that appears in the section at least once, using the exact original spelling, capitalization, punctuation, isotopic labels, brackets, hyphens, salts, buffer names, and parenthetical qualifiers. Treat distinct case/format variants as distinct names (e.g., [1-13C]pyruvic acid and [1-13C]Pyruvic acid are separate and each must appear once).- Examples you must preserve verbatim when present: Hyperpolarized Pyruvate (13C) Injection; non-polarized Pyruvate Injection; Pyruvate (13C) Injection; hyperpolarized [1-13C]pyruvate; Mixture of [1-13C]pyruvic acid and 15 mM AH111501 sodium salt; TRIS/EDTA buffer solution; TRIS; NaOH; Na2EDTA; [1-13C]pyruvic acid; AH111501 sodium salt.- Also preserve exact study identifiers, batch codes, section numbers, regulatory citations, and instrument parameters as written (e.g., GE-101-001, GE-101-003, USP <797>, 3.2.P.5.2.5, FFF106/140-806, FFF106/142-806, 3T MRI, 5 degree RF pulse, TR=3s, 90 degree pulse, 64 averages, TR=10s, 10 μl Gd/ml solution).Content prioritization (if space is tight)1) What the section is about (topic/purpose).2) All named chemical entities and compositions (list all chemical names at least once; include concentrations/amounts if given).3) Critical process/handling facts (e.g., aseptic processing vs terminal sterilization; ISO classifications; filtration specs; compounding/filling steps; temperatures/times/volumes; storage/administration limits).4) Container/packaging specifics (e.g., cryovials, “sterile fluid path”).5) Microbiological/testing/regulatory details (e.g., sterility/pyrogenicity testing timing; USP <797>; state board compliance; site/manufacturer if stated).6) Overages/single-dose formulas and key quantities.Numerical fidelity- Preserve all critical numbers and units exactly (e.g., 1.44 g, 27.7 mg, 15 mM, 18 mL, 1.47 g, two 0.2 μm filters, ISO 7, ISO 5, 38 mL).- Include testing/analysis parameters when present (e.g., polarization/relaxation time (T1); number of spectra; pulse angles; TR values; MRI location relative to clean room).Style and compression- Be neutral and factual; do not infer unstated information.- Consolidate repeated statements; compress lists with commas/semicolons to save words.- Mention tables/figures only to convey key data; do not reproduce them.- If many chemicals are present, ensure each distinct name appears once; group them succinctly.- Avoid symbols or special formatting not in the source text.Common domain cues to include when present- Aseptic processing vs terminal sterilization and the rationale/timing (e.g., “tested for sterility and pyrogenicity subsequent to patient administration”).- Environmental/processing controls (ISO 7/ISO 5; LAF unit; filtration; filling/weight targets per cryovial).- Site/regulatory context (e.g., USP <797>; California State Board of Pharmacy; University of California, San Francisco Department of Clinical Pharmacy).- Study/kit equivalence statements (e.g., equivalence to GE-101-001/GE-101-003 formulations).- QC/measurement methods (e.g., capacitive threshold at Administration syringe nominal 38 mL).Self-check before finalizing- Does the paragraph contain every distinct chemical name exactly as written in the section (including case and notation variants)?- Is the summary 45–70 words (≤90), in a single paragraph?- Are the most critical process/regulatory/testing details and all key numbers preserved without unnecessary verbosity?`