Searching for relevant information can sometimes feel like looking for a needle in a haystack, but don’t despair, GPTs can actually do a lot of this work for us. In this guide we explore a way to augment existing search systems with various AI techniques, helping us sift through the noise.
Two ways of retrieving information for GPT are:
- Mimicking Human Browsing: GPT triggers a search, evaluates the results, and modifies the search query if necessary. It can also follow up on specific search results to form a chain of thought, much like a human user would do.
- Retrieval with Embeddings: Calculate embeddings for your content and a user query, and then retrieve the content most related as measured by cosine similarity. This technique is used heavily by search engines like Google.
These approaches are both promising, but each has their shortcomings: the first one can be slow due to its iterative nature and the second one requires embedding your entire knowledge base in advance, continuously embedding new content and maintaining a vector database.
By combining these approaches, and drawing inspiration from re-ranking methods, we identify an approach that sits in the middle. This approach can be implemented on top of any existing search system, like the Slack search API, or an internal ElasticSearch instance with private data. Here’s how it works:
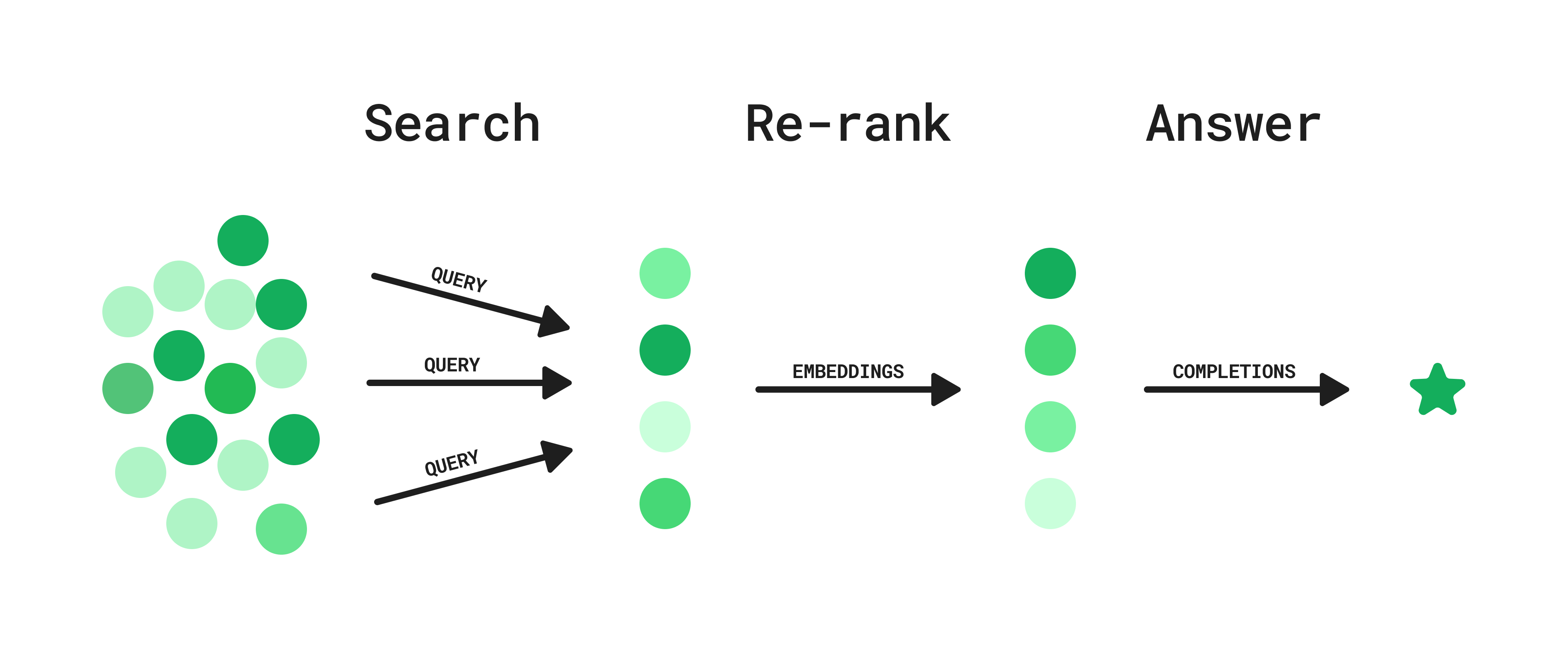
Step 1: Search
- User asks a question.
- GPT generates a list of potential queries.
- Search queries are executed in parallel.
Step 2: Re-rank
- Embeddings for each result are used to calculate semantic similarity to a generated hypothetical ideal answer to the user question.
- Results are ranked and filtered based on this similarity metric.
Step 3: Answer
- Given the top search results, the model generates an answer to the user’s question, including references and links.
This hybrid approach offers relatively low latency and can be integrated into any existing search endpoint, without requiring the upkeep of a vector database. Let's dive into it! We will use the News API as an example domain to search over.
Setup
In addition to your OPENAI_API_KEY, you'll have to include a NEWS_API_KEY in your environment. You can get an API key here.