By leveraging the Responses API with OpenAI’s latest reasoning models, you can unlock higher intelligence, lower costs, and more efficient token usage in your applications. The API also enables access to reasoning summaries, supports features like hosted-tool use, and is designed to accommodate upcoming enhancements for even greater flexibility and performance.
We've recently released two new state-of-the-art reasoning models, o3 and o4-mini, that excel at combining reasoning capabilities with agentic tool use. What many folks don't know is that you can improve their performance by fully leveraging our (relatively) new Responses API. This cookbook shows how to get the most out of these models and explores how reasoning and function calling work behind the scenes. By giving the model access to previous reasoning items, we can ensure it operates at maximum intelligence and lowest cost.
We introduced the Responses API with a separate cookbook and API reference. The main takeaway: the Responses API is similar to the Completions API, but with improvements and added features. We've also rolled out encrypted content for Responses, making it even more useful for those who can't use the API in a stateful way!
Before we dive into how the Responses API can help, let's quickly review how reasoning models work. Models like o3 and o4-mini break problems down step by step, producing an internal chain of thought that encodes their reasoning. For safety, these reasoning tokens are only exposed to users in summarized form.
In a multistep conversation, the reasoning tokens are discarded after each turn while input and output tokens from each step are fed into the next
From the JSON dump of the response object, you can see that in addition to the output_text, the model also produces a reasoning item. This item represents the model's internal reasoning tokens and is exposed as an ID—here, for example, rs_6820f383d7c08191846711c5df8233bc0ac5ba57aafcbac7. Because the Responses API is stateful, these reasoning tokens persist: just include their IDs in subsequent messages to give future responses access to the same reasoning items. If you use previous_response_id for multi-turn conversations, the model will automatically have access to all previously produced reasoning items.
You can also see how many reasoning tokens the model generated. For example, with 10 input tokens, the response included 148 output tokens—128 of which are reasoning tokens not shown in the final assistant message.
Wait—didn’t the diagram show that reasoning from previous turns is discarded? So why bother passing it back in later turns?
Great question! In typical multi-turn conversations, you don’t need to include reasoning items or tokens—the model is trained to produce the best output without them. However, things change when tool use is involved. If a turn includes a function call (which may require an extra round trip outside the API), you do need to include the reasoning items—either via previous_response_id or by explicitly adding the reasoning item to input. Let’s see how this works with a quick function-calling example.
import requestsdefget_weather(latitude, longitude): response = requests.get(f"https://api.open-meteo.com/v1/forecast?latitude={latitude}&longitude={longitude}¤t=temperature_2m,wind_speed_10m&hourly=temperature_2m,relative_humidity_2m,wind_speed_10m") data = response.json()return data['current']['temperature_2m']tools = [{"type": "function","name": "get_weather","description": "Get current temperature for provided coordinates in celsius.","parameters": {"type": "object","properties": {"latitude": {"type": "number"},"longitude": {"type": "number"} },"required": ["latitude", "longitude"],"additionalProperties": False },"strict": True}]context = [{"role": "user", "content": "What's the weather like in Paris today?"}]response = client.responses.create(model="o4-mini",input=context,tools=tools,)response.output
After some reasoning, the o4-mini model determines it needs more information and calls a function to get it. We can call the function and return its output to the model. Crucially, to maximize the model’s intelligence, we should include the reasoning item by simply adding all of the output back into the context for the next turn.
context += response.output # Add the response to the context (including the reasoning item)tool_call = response.output[1]args = json.loads(tool_call.arguments)# calling the functionresult = get_weather(args["latitude"], args["longitude"]) context.append({ "type": "function_call_output","call_id": tool_call.call_id,"output": str(result)})# we are calling the api again with the added function call output. Note that while this is another API call, we consider this as a single turn in the conversation.response_2 = client.responses.create(model="o4-mini",input=context,tools=tools,)print(response_2.output_text)
The current temperature in Paris is 16.3°C. If you’d like more details—like humidity, wind speed, or a brief description of the sky—just let me know!
While this toy example may not clearly show the benefits—since the model will likely perform well with or without the reasoning item—our own tests found otherwise. On a more rigorous benchmark like SWE-bench, including reasoning items led to about a 3% improvement for the same prompt and setup.
As shown above, reasoning models generate both reasoning tokens and completion tokens, which the API handles differently. This distinction affects how caching works and impacts both performance and latency. The following diagram illustrates these concepts:
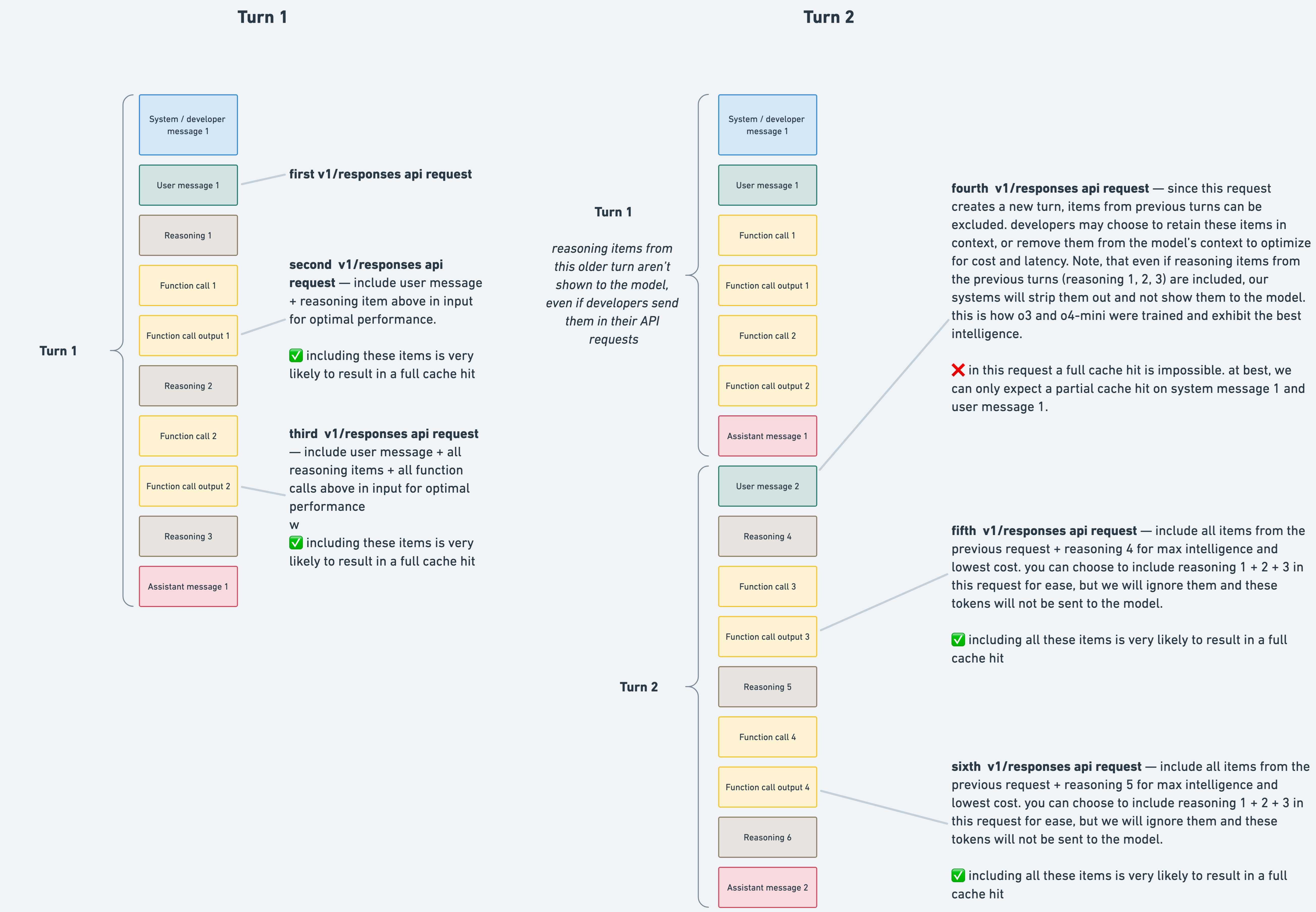
In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns. As a result, the fourth API call in the diagram cannot achieve a full cache hit, because those reasoning items are missing from the prompt. However, including them is harmless—the API will simply discard any reasoning items that aren’t relevant for the current turn. Keep in mind that caching only impacts prompts longer than 1024 tokens. In our tests, switching from the Completions API to the Responses API boosted cache utilization from 40% to 80%. Higher cache utilization leads to lower costs (for example, cached input tokens for o4-mini are 75% cheaper than uncached ones) and improved latency.
Some organizations—such as those with Zero Data Retention (ZDR) requirements—cannot use the Responses API in a stateful way due to compliance or data retention policies. To support these cases, OpenAI offers encrypted reasoning items, allowing you to keep your workflow stateless while still benefiting from reasoning items.
To use encrypted reasoning items:
Add ["reasoning.encrypted_content"] to the include field in your API call.
The API will return an encrypted version of the reasoning tokens, which you can pass back in future requests just like regular reasoning items.
For ZDR organizations, OpenAI enforces store=false automatically. When a request includes encrypted_content, it is decrypted in-memory (never written to disk), used for generating the next response, and then securely discarded. Any new reasoning tokens are immediately encrypted and returned to you, ensuring no intermediate state is ever persisted.
Here’s a quick code update to show how this works:
context = [{"role": "user", "content": "What's the weather like in Paris today?"}]response = client.responses.create(model="o3",input=context,tools=tools,store=False, #store=false, just like how ZDR is enforcedinclude=["reasoning.encrypted_content"] # Encrypted chain of thought is passed back in the response)
# take a look at the encrypted reasoning itemprint(response.output[0])
With include=["reasoning.encrypted_content"] set, we now see an encrypted_content field in the reasoning item being passed back. This encrypted content represents the model's reasoning state, persisted entirely on the client side with OpenAI retaining no data. We can then pass this back just as we did with the reasoning item before.
context += response.output # Add the response to the context (including the encrypted chain of thought)tool_call = response.output[1]args = json.loads(tool_call.arguments)result =20#mocking the result of the function callcontext.append({ "type": "function_call_output","call_id": tool_call.call_id,"output": str(result)})response_2 = client.responses.create(model="o3",input=context,tools=tools,store=False,include=["reasoning.encrypted_content"])print(response_2.output_text)
It’s currently about 20 °C in Paris.
With a simple change to the include field, we can now pass back the encrypted reasoning item and use it to improve the model's performance in intelligence, cost, and latency.
Now you should be fully equipped with the knowledge to fully utilize our latest reasoning models!
Another useful feature in the Responses API is that it supports reasoning summaries. While we do not expose the raw chain of thought tokens, users can access their summaries.
# Make a hard call to o3 with reasoning summary includedresponse = client.responses.create(model="o3",input="What are the main differences between photosynthesis and cellular respiration?",reasoning={"summary": "auto"},)# Extract the first reasoning summary text from the response objectfirst_reasoning_item = response.output[0] # Should be a ResponseReasoningItemfirst_summary_text = first_reasoning_item.summary[0].text if first_reasoning_item.summary elseNoneprint("First reasoning summary text:\n", first_summary_text)
First reasoning summary text:
**Analyzing biological processes**
I think the user is looking for a clear explanation of the differences between certain processes. I should create a side-by-side comparison that lists out key elements like the formulas, energy flow, locations, reactants, products, organisms involved, electron carriers, and whether the processes are anabolic or catabolic. This structured approach will help in delivering a comprehensive answer. It’s crucial to cover all aspects to ensure the user understands the distinctions clearly.
Reasoning summary text lets you give users a window into the model’s thought process. For example, during conversations with multiple function calls, users can see both which functions were called and the reasoning behind each call—without waiting for the final assistant message. This adds transparency and interactivity to your application’s user experience.
By leveraging the OpenAI Responses API and the latest reasoning models, you can unlock higher intelligence, improved transparency, and greater efficiency in your applications. Whether you’re utilizing reasoning summaries, encrypted reasoning items for compliance, or optimizing for cost and latency, these tools empower you to build more robust and interactive AI experiences.
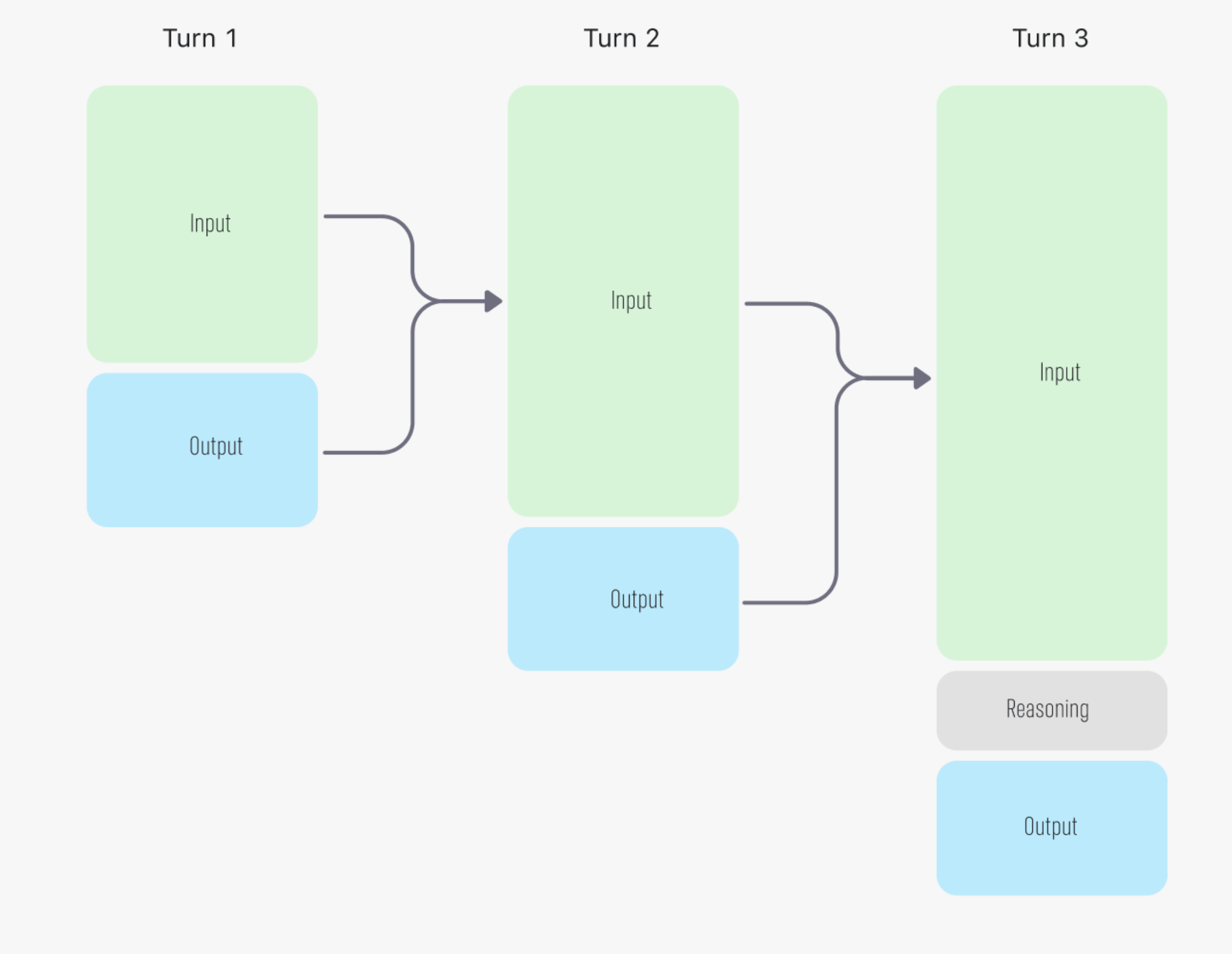 Diagram borrowed from our
Diagram borrowed from our