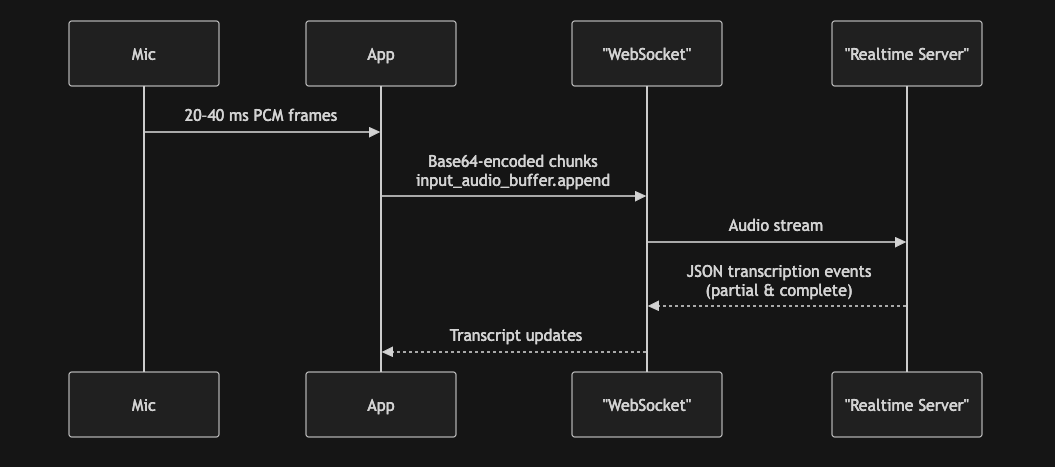
TARGET_SR = 24_000
PCM_SCALE = 32_767
CHUNK_SAMPLES = 3_072 # ≈128 ms at 24 kHz
RT_URL = "wss://api.openai.com/v1/realtime?intent=transcription"
EV_DELTA = "conversation.item.input_audio_transcription.delta"
EV_DONE = "conversation.item.input_audio_transcription.completed"
# ── helpers ────────────────────────────────────────────────────────────────
def float_to_16bit_pcm(float32_array):
clipped = [max(-1.0, min(1.0, x)) for x in float32_array]
pcm16 = b''.join(struct.pack('<h', int(x * 32767)) for x in clipped)
return pcm16
def base64_encode_audio(float32_array):
pcm_bytes = float_to_16bit_pcm(float32_array)
encoded = base64.b64encode(pcm_bytes).decode('ascii')
return encoded
def load_and_resample(path: str, sr: int = TARGET_SR) -> np.ndarray:
"""Return mono PCM-16 as a NumPy array."""
data, file_sr = sf.read(path, dtype="float32")
if data.ndim > 1:
data = data.mean(axis=1)
if file_sr != sr:
data = resampy.resample(data, file_sr, sr)
return data
async def _send_audio(ws, pcm: np.ndarray, chunk: int, sr: int) -> None:
"""Producer: stream base-64 chunks at real-time pace, then signal EOF."""
dur = 0.025 # Add pacing to ensure real-time transcription
t_next = time.monotonic()
for i in range(0, len(pcm), chunk):
float_chunk = pcm[i:i + chunk]
payload = {
"type": "input_audio_buffer.append",
"audio": base64_encode_audio(float_chunk),
}
await ws.send(json.dumps(payload))
t_next += dur
await asyncio.sleep(max(0, t_next - time.monotonic()))
await ws.send(json.dumps({"type": "input_audio_buffer.end"}))
async def _recv_transcripts(ws, collected: List[str]) -> None:
"""
Consumer: build `current` from streaming deltas, promote it to `collected`
whenever a …completed event arrives, and flush the remainder on socket
close so no words are lost.
"""
current: List[str] = []
try:
async for msg in ws:
ev = json.loads(msg)
typ = ev.get("type")
if typ == EV_DELTA:
delta = ev.get("delta")
if delta:
current.append(delta)
print(delta, end="", flush=True)
elif typ == EV_DONE:
# sentence finished → move to permanent list
collected.append("".join(current))
current.clear()
except websockets.ConnectionClosedOK:
pass
# socket closed → flush any remaining partial sentence
if current:
collected.append("".join(current))
def _session(model: str, vad: float = 0.5) -> dict:
return {
"type": "transcription_session.update",
"session": {
"input_audio_format": "pcm16",
"turn_detection": {"type": "server_vad", "threshold": vad},
"input_audio_transcription": {"model": model},
},
}
async def transcribe_audio_async(
wav_path,
api_key,
*,
model: str = MODEL_NAME,
chunk: int = CHUNK_SAMPLES,
) -> str:
pcm = load_and_resample(wav_path)
headers = {"Authorization": f"Bearer {api_key}", "OpenAI-Beta": "realtime=v1"}
async with websockets.connect(RT_URL, additional_headers=headers, max_size=None) as ws:
await ws.send(json.dumps(_session(model)))
transcripts: List[str] = []
await asyncio.gather(
_send_audio(ws, pcm, chunk, TARGET_SR),
_recv_transcripts(ws, transcripts),
) # returns when server closes
return " ".join(transcripts)