This notebook provides step by step instuctions on using Azure AI Search (f.k.a Azure Cognitive Search) as a vector database with OpenAI embeddings, then creating an Azure Function on top to plug into a Custom GPT in ChatGPT.
This can be a solution for customers looking to set up RAG infrastructure contained within Azure, and exposing it as an endpoint to integrate that with other platforms such as ChatGPT.
Azure AI Search is a cloud search service that gives developers infrastructure, APIs, and tools for building a rich search experience over private, heterogeneous content in web, mobile, and enterprise applications.
Azure Functions is a serverless compute service that runs event-driven code, automatically managing infrastructure, scaling, and integrating with other Azure services.
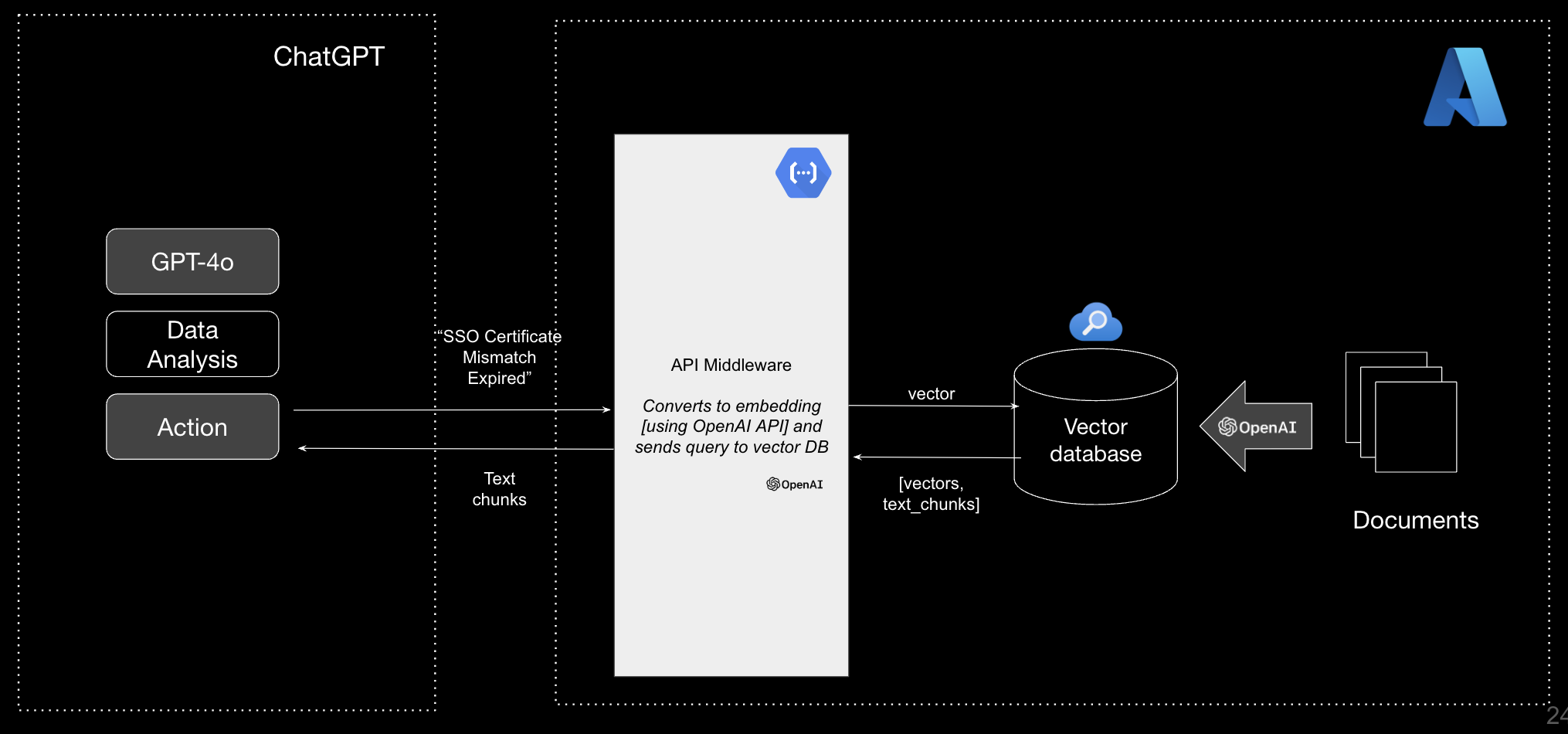
Below is a diagram of the architecture of this solution, which we'll walk through step-by-step.
Note: This architecture pattern of vector data store + serverless functions can be extrapolated to other vector data stores. For example, if you would want to use something like Postgres within Azure, you'd change the Configure Azure AI Search Settings step to set-up the requirements for Postgres, you'd modify the Create Azure AI Vector Search to create the database and table in Postgres instead, and you'd update the function_app.py code in this repository to query Postgres instead of Azure AI Search. The data preparation and creation of the Azure Function would stay consistent.
Prepare Data Prepare the data for uploading by embedding the documents, as well as capturing additional metadata. We will use a subset of OpenAI's docs as example data for this.
Before going through this section, make sure you have your OpenAI API key.
openai_api_key = os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as an env var>") # Saving this as a variable to reference in function app in later stepopenai_client = OpenAI(api_key=openai_api_key)embeddings_model ="text-embedding-3-small"# We'll use this by default, but you can change to your text-embedding-3-large if desired
# Update the below with your valuessubscription_id="<enter_your_subscription_id>"resource_group="<enter_your_resource_group>"## Make sure to choose a region that supports the proper products. We've defaulted to "eastus" below. https://azure.microsoft.com/en-us/explore/global-infrastructure/products-by-region/#products-by-region_tab5region ="eastus"credential = InteractiveBrowserCredential()subscription_client = SubscriptionClient(credential)subscription =next(subscription_client.subscriptions.list())
Below we'll generate a unique name for the search service, set up the service properties, and create the search service.
# Initialize the SearchManagementClient with the provided credentials and subscription IDsearch_management_client = SearchManagementClient(credential=credential,subscription_id=subscription_id,)# Generate a unique name for the search service using UUID, but you can change this if you'd like.generated_uuid =str(uuid.uuid4())search_service_name ="search-service-gpt-demo"+ generated_uuid## The below is the default endpoint structure that is created when you create a search service. This may differ based on your Azure settings.search_service_endpoint ='https://'+search_service_name+'.search.windows.net'# Create or update the search service with the specified parametersresponse = search_management_client.services.begin_create_or_update(resource_group_name=resource_group,search_service_name=search_service_name,service={"location": region,"properties": {"hostingMode": "default", "partitionCount": 1, "replicaCount": 1},# We are using the free pricing tier for this demo. You are only allowed one free search service per subscription."sku": {"name": "free"},"tags": {"app-name": "Search service demo"}, },).result()# Convert the response to a dictionary and then to a pretty-printed JSON stringresponse_dict = response.as_dict()response_json = json.dumps(response_dict, indent=4)print(response_json)print("Search Service Name:"+ search_service_name)print("Search Service Endpoint:"+ search_service_endpoint)
Now that we have the search service up and running, we need the Search Service API Key, which we'll use to initiate the index creation, and later to execute the search.
# Retrieve the admin keys for the search servicetry: response = search_management_client.admin_keys.get(resource_group_name=resource_group,search_service_name=search_service_name, )# Extract the primary API key from the response and save as a variable to be used later search_service_api_key = response.primary_keyprint("Successfully retrieved the API key.")exceptExceptionas e:print(f"Failed to retrieve the API key: {e}")
We're going to embed and store a few pages of the OpenAI docs in the oai_docs folder. We'll first embed each, add it to a CSV, and then use that CSV to upload to the index.
In order to handle longer text files beyond the context of 8191 tokens, we can either use the chunk embeddings separately, or combine them in some way, such as averaging (weighted by the size of each chunk).
We will take a function from Python's own cookbook that breaks up a sequence into chunks.
defbatched(iterable, n):"""Batch data into tuples of length n. The last batch may be shorter."""# batched('ABCDEFG', 3) --> ABC DEF Gif n <1:raiseValueError('n must be at least one') it =iter(iterable)while (batch :=tuple(islice(it, n))):yield batch
Now we define a function that encodes a string into tokens and then breaks it up into chunks. We'll use tiktoken, a fast open-source tokenizer by OpenAI.
To read more about counting tokens with Tiktoken, check out this cookbook.
defchunked_tokens(text, chunk_length, encoding_name='cl100k_base'):# Get the encoding object for the specified encoding name. OpenAI's tiktoken library, which is used in this notebook, currently supports two encodings: 'bpe' and 'cl100k_base'. The 'bpe' encoding is used for GPT-3 and earlier models, while 'cl100k_base' is used for newer models like GPT-4. encoding = tiktoken.get_encoding(encoding_name)# Encode the input text into tokens tokens = encoding.encode(text)# Create an iterator that yields chunks of tokens of the specified length chunks_iterator = batched(tokens, chunk_length)# Yield each chunk from the iteratoryield from chunks_iterator
Finally, we can write a function that safely handles embedding requests, even when the input text is longer than the maximum context length, by chunking the input tokens and embedding each chunk individually. The average flag can be set to True to return the weighted average of the chunk embeddings, or False to simply return the unmodified list of chunk embeddings.
Note: there are other, more sophisticated techniques you can take here, including:
using GPT-4o to capture images/chart descriptions for embedding.
keeping text overlap between the chunks to minimize cutting off important context.
chunking based on paragraphs or sections.
adding more descriptive metadata about each article.
## Change the below based on model. The below is for the latest embeddings models from OpenAI, so you can leave as is unless you are using a different embedding model..EMBEDDING_CTX_LENGTH=8191EMBEDDING_ENCODING='cl100k_base'
defgenerate_embeddings(text, model):# Generate embeddings for the provided text using the specified model embeddings_response = openai_client.embeddings.create(model=model, input=text)# Extract the embedding data from the response embedding = embeddings_response.data[0].embeddingreturn embeddingdeflen_safe_get_embedding(text, model=embeddings_model, max_tokens=EMBEDDING_CTX_LENGTH, encoding_name=EMBEDDING_ENCODING):# Initialize lists to store embeddings and corresponding text chunks chunk_embeddings = [] chunk_texts = []# Iterate over chunks of tokens from the input textfor chunk in chunked_tokens(text, chunk_length=max_tokens, encoding_name=encoding_name):# Generate embeddings for each chunk and append to the list chunk_embeddings.append(generate_embeddings(chunk, model=model))# Decode the chunk back to text and append to the list chunk_texts.append(tiktoken.get_encoding(encoding_name).decode(chunk))# Return the list of chunk embeddings and the corresponding text chunksreturn chunk_embeddings, chunk_texts
Next, we can define a helper function that will capture additional metadata about the documents. This is useful to use as a metadata filter for search queries, and capturing richer data for search.
In this example, I'll choose from a list of categories to use later on in a metadata filter.
## These are the categories I will be using for the categorization task. You can change these as needed based on your use case.categories = ['authentication','models','techniques','tools','setup','billing_limits','other']defcategorize_text(text, categories):# Create a prompt for categorization messages = [ {"role": "system", "content": f"""You are an expert in LLMs, and you will be given text that corresponds to an article in OpenAI's documentation. Categorize the document into one of these categories: {', '.join(categories)}. Only respond with the category name and nothing else."""}, {"role": "user", "content": text} ]try:# Call the OpenAI API to categorize the text response = openai_client.chat.completions.create(model="gpt-4o",messages=messages )# Extract the category from the response category = response.choices[0].message.contentreturn categoryexceptExceptionas e:print(f"Error categorizing text: {str(e)}")returnNone
Now, we can define some helper functions to process the .txt files in the oai_docs folder within the data folder. You can use this with your own data as well and supports both .txt and .pdf files.
defextract_text_from_pdf(pdf_path):# Initialize the PDF reader reader = PdfReader(pdf_path) text =""# Iterate through each page in the PDF and extract textfor page in reader.pages: text += page.extract_text()return textdefprocess_file(file_path, idx, categories, embeddings_model): file_name = os.path.basename(file_path)print(f"Processing file {idx +1}: {file_name}")# Read text content from .txt filesif file_name.endswith('.txt'):withopen(file_path, 'r', encoding='utf-8') asfile: text =file.read()# Extract text content from .pdf fileselif file_name.endswith('.pdf'): text = extract_text_from_pdf(file_path) title = file_name# Generate embeddings for the title title_vectors, title_text = len_safe_get_embedding(title, embeddings_model)print(f"Generated title embeddings for {file_name}")# Generate embeddings for the content content_vectors, content_text = len_safe_get_embedding(text, embeddings_model)print(f"Generated content embeddings for {file_name}") category = categorize_text(' '.join(content_text), categories)print(f"Categorized {file_name} as {category}")# Prepare the data to be appended data = []for i, content_vector inenumerate(content_vectors): data.append({"id": f"{idx}_{i}","vector_id": f"{idx}_{i}","title": title_text[0],"text": content_text[i],"title_vector": json.dumps(title_vectors[0]), # Assuming title is short and has only one chunk"content_vector": json.dumps(content_vector),"category": category })print(f"Appended data for chunk {i +1}/{len(content_vectors)} of {file_name}")return data
We'll now use this helper function to process our OpenAI documentation. Feel free to update this to use your own data by changing the folder in process_files below.
Note that this will process the documents in chosen folder concurrently, so this should take <30 seconds if using txt files, and slightly longer if using PDFs.
## Customize the location below if you are using different data besides the OpenAI documentation. Note that if you are using a different dataset, you will need to update the categories list as well.folder_name ="../../../data/oai_docs"files = [os.path.join(folder_name, f) for f in os.listdir(folder_name) if f.endswith('.txt') or f.endswith('.pdf')]data = []# Process each file concurrentlywith concurrent.futures.ThreadPoolExecutor() as executor: futures = {executor.submit(process_file, file_path, idx, categories, embeddings_model): idx for idx, file_path inenumerate(files)}for future in concurrent.futures.as_completed(futures):try: result = future.result() data.extend(result)exceptExceptionas e:print(f"Error processing file: {str(e)}")# Write the data to a CSV filecsv_file = os.path.join("..", "embedded_data.csv")withopen(csv_file, 'w', newline='', encoding='utf-8') as csvfile: fieldnames = ["id", "vector_id", "title", "text", "title_vector", "content_vector","category"] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader()for row in data: writer.writerow(row)print(f"Wrote row with id {row['id']} to CSV")# Convert the CSV file to a Dataframearticle_df = pd.read_csv("../embedded_data.csv")# Read vectors from strings back into a list using json.loadsarticle_df["title_vector"] = article_df.title_vector.apply(json.loads)article_df["content_vector"] = article_df.content_vector.apply(json.loads)article_df["vector_id"] = article_df["vector_id"].apply(str)article_df["category"] = article_df["category"].apply(str)article_df.head()
We now have an embedded_data.csv file with six columns that we can upload to our vector database!
We'll define and create a search index using the SearchIndexClient from the Azure AI Search Python SDK. The index incorporates both vector search and hybrid search capabilities. For more details, visit Microsoft's documentation on how to Create a Vector Index
index_name ="azure-ai-search-openai-cookbook-demo"# index_name = "<insert_name_for_index>"index_client = SearchIndexClient(endpoint=search_service_endpoint, credential=AzureKeyCredential(search_service_api_key))# Define the fields for the index. Update these based on your data.# Each field represents a column in the search indexfields = [ SimpleField(name="id", type=SearchFieldDataType.String), # Simple string field for document ID SimpleField(name="vector_id", type=SearchFieldDataType.String, key=True), # Key field for the index# SimpleField(name="url", type=SearchFieldDataType.String), # URL field (commented out) SearchableField(name="title", type=SearchFieldDataType.String), # Searchable field for document title SearchableField(name="text", type=SearchFieldDataType.String), # Searchable field for document text SearchField(name="title_vector",type=SearchFieldDataType.Collection(SearchFieldDataType.Single), # Collection of single values for title vectorvector_search_dimensions=1536, # Number of dimensions in the vectorvector_search_profile_name="my-vector-config", # Profile name for vector search configuration ), SearchField(name="content_vector",type=SearchFieldDataType.Collection(SearchFieldDataType.Single), # Collection of single values for content vectorvector_search_dimensions=1536, # Number of dimensions in the vectorvector_search_profile_name="my-vector-config", # Profile name for vector search configuration ), SearchableField(name="category", type=SearchFieldDataType.String, filterable=True), # Searchable field for document category]# This configuration defines the algorithm and parameters for vector searchvector_search = VectorSearch(algorithms=[ HnswAlgorithmConfiguration(name="my-hnsw", # Name of the HNSW algorithm configurationkind=VectorSearchAlgorithmKind.HNSW, # Type of algorithmparameters=HnswParameters(m=4, # Number of bi-directional links created for every new elementef_construction=400, # Size of the dynamic list for the nearest neighbors during constructionef_search=500, # Size of the dynamic list for the nearest neighbors during searchmetric=VectorSearchAlgorithmMetric.COSINE, # Distance metric used for the search ), ) ],profiles=[ VectorSearchProfile(name="my-vector-config", # Name of the vector search profilealgorithm_configuration_name="my-hnsw", # Reference to the algorithm configuration ) ],)# Create the search index with the vector search configuration# This combines all the configurations into a single search indexindex = SearchIndex(name=index_name, # Name of the indexfields=fields, # Fields defined for the indexvector_search=vector_search # Vector search configuration)# Create or update the index# This sends the index definition to the Azure Search serviceresult = index_client.create_index(index)print(f"{result.name} created") # Output the name of the created index
Now we'll upload the articles from above that we've stored in embedded_data.csv from a pandas DataFrame to an Azure AI Search index. For a detailed guide on data import strategies and best practices, refer to Data Import in Azure AI Search.
# Convert the 'id' and 'vector_id' columns to string so one of them can serve as our key fieldarticle_df["id"] = article_df["id"].astype(str)article_df["vector_id"] = article_df["vector_id"].astype(str)# Convert the DataFrame to a list of dictionariesdocuments = article_df.to_dict(orient="records")# Log the number of documents to be uploadedprint(f"Number of documents to upload: {len(documents)}")# Create a SearchIndexingBufferedSenderbatch_client = SearchIndexingBufferedSender( search_service_endpoint, index_name, AzureKeyCredential(search_service_api_key))# Get the first document to check its schemafirst_document = documents[0]# Get the index schemaindex_schema = index_client.get_index(index_name)# Get the field names from the index schemaindex_fields = {field.name: field.type for field in index_schema.fields}# Check each field in the first documentfor field, value in first_document.items():if field notin index_fields:print(f"Field '{field}' is not in the index schema.")# Check for any fields in the index schema that are not in the documentsfor field in index_fields:if field notin first_document:print(f"Field '{field}' is in the index schema but not in the documents.")try:if documents:# Add upload actions for all documents in a single call upload_result = batch_client.upload_documents(documents=documents)# Check if the upload was successful# Manually flush to send any remaining documents in the buffer batch_client.flush()print(f"Uploaded {len(documents)} documents in total")else:print("No documents to upload.")except HttpResponseError as e:print(f"An error occurred: {e}")raise# Re-raise the exception to ensure it errors outfinally:# Clean up resources batch_client.close()
Now that the data is uploaded, we'll test both vector similarity search and hybrid search locally below to make sure it is working as expected.
You can test both a pure vector search and hybrid search. Pure vector search passes in None to the search_text below and will only search on vector similarity. Hybrid search will combines the capabilities of traditional keyword-based search by passing in the query text query to the search_text with vector-based similarity search to provide more relevant and contextual results.
query ="What model should I use to embed?"# Note: we'll have the GPT choose the category automatically once we put it in ChatGPTcategory ="models"search_client = SearchClient(search_service_endpoint, index_name, AzureKeyCredential(search_service_api_key))vector_query = VectorizedQuery(vector=generate_embeddings(query, embeddings_model), k_nearest_neighbors=3, fields="content_vector")results = search_client.search( search_text=None, # Pass in None if you want to use pure vector search, and `query` if you want to use hybrid searchvector_queries= [vector_query], select=["title", "text"],filter=f"category eq '{category}'")for result in results: print(result)
Azure Functions are an easy way to build an API on top of our new AI search. Our code (see the function_app.py file in this folder, or linked here) does the following:
Takes in an input of the user's query, search index endpoint, the index name, the k_nearest_neighbors*, the search column to use (either content_vector or title_vector), and whether it should use a hybrid query
Takes the user's query and embeds it.
Conducts a vector search and retrieves relevant text chunks.
Returns those relevant text chunks as the response body.
*In the context of vector search, k_nearest_neighbors specifies the number of "closest" vectors (in terms of cosine similarity) that the search should return. For example, if k_nearest_neighbors is set to 3, the search will return the 3 vectors in the index that are most similar to the query vector.
Note that this Azure Function does not have any authentication. However, you can set authentication on it following docs here
We can create a new storage account using the code below, but feel free to skip that block and modify the subsequent steps to use an existing storage account. This may take up to 30 seconds.
## Update below with a different namestorage_account_name ="<enter-storage-account-name>"## Use below SKU or any other SKU as per your requirementsku ="Standard_LRS"resource_client = ResourceManagementClient(credential, subscription_id)storage_client = StorageManagementClient(credential, subscription_id)# Create resource group if it doesn't existrg_result = resource_client.resource_groups.create_or_update(resource_group, {"location": region})# Create storage accountstorage_async_operation = storage_client.storage_accounts.begin_create( resource_group, storage_account_name, {"sku": {"name": sku},"kind": "StorageV2","location": region, },)storage_account = storage_async_operation.result()print(f"Storage account {storage_account.name} created")
This Function App is where the python code will execute once it is triggered via a GPT Action. To read more about Function Apps, see the docs here.
To deploy Function Apps, we'll need to use the Azure CLI and Azure Functions Core Tools.
The below will attempt to install it and run it based on your platform type in your virtual environment, but if that does not work, read the Azure documentation to figure out how to install Azure Function Core Tools and Azure CLI. After doing that, run the below subprocess.run commands in your terminal after navigating to this folder.
First we'll make sure we have the relevant tools in the environment in order to run the Azure commands necessary. This may take a few minutes to install.
os_type = platform.system()if os_type =="Windows":# Install Azure Functions Core Tools on Windows subprocess.run(["npm", "install", "-g", "azure-functions-core-tools@3", "--unsafe-perm", "true"], check=True)# Install Azure CLI on Windows subprocess.run(["powershell", "-Command", "Invoke-WebRequest -Uri https://aka.ms/installazurecliwindows -OutFile .\\AzureCLI.msi; Start-Process msiexec.exe -ArgumentList '/I AzureCLI.msi /quiet' -Wait"], check=True)elif os_type =="Darwin": # MacOS# Install Azure Functions Core Tools on MacOSif platform.machine() =='arm64':# For M1 Macs subprocess.run(["arch", "-arm64", "brew", "install", "azure-functions-core-tools@3"], check=True)else:# For Intel Macs subprocess.run(["brew", "install", "azure-functions-core-tools@3"], check=True)# Install Azure CLI on MacOS subprocess.run(["brew", "update"], check=True) subprocess.run(["brew", "install", "azure-cli"], check=True)elif os_type =="Linux":# Install Azure Functions Core Tools on Linux subprocess.run(["curl", "https://packages.microsoft.com/keys/microsoft.asc", "|", "gpg", "--dearmor", ">", "microsoft.gpg"], check=True, shell=True) subprocess.run(["sudo", "mv", "microsoft.gpg", "/etc/apt/trusted.gpg.d/microsoft.gpg"], check=True) subprocess.run(["sudo", "sh", "-c", "'echo \"deb [arch=amd64] https://packages.microsoft.com/repos/microsoft-ubuntu-$(lsb_release -cs)-prod $(lsb_release -cs) main\" > /etc/apt/sources.list.d/dotnetdev.list'"], check=True, shell=True) subprocess.run(["sudo", "apt-get", "update"], check=True) subprocess.run(["sudo", "apt-get", "install", "azure-functions-core-tools-3"], check=True)# Install Azure CLI on Linux subprocess.run(["curl", "-sL", "https://aka.ms/InstallAzureCLIDeb", "|", "sudo", "bash"], check=True, shell=True)else:# Raise an error if the operating system is not supportedraiseOSError("Unsupported operating system")# Verify the installation of Azure Functions Core Toolssubprocess.run(["func", "--version"], check=True)# Verify the installation of Azure CLIsubprocess.run(["az", "--version"], check=True)subprocess.run(["az", "login"], check=True)
Now, we need to create a local.settings.json file with our key environment variables for Azure
Check the local.settings.json file and make sure that the environment variables match what you expect.
Now, give your app a name below, and you are ready to create your Function App and then publish your function.
# Replace this with your own values. This name will appear in the URL of the API call https://<app_name>.azurewebsites.netapp_name ="<app-name>"subprocess.run(["az", "functionapp", "create","--resource-group", resource_group,"--consumption-plan-location", region,"--runtime", "python","--name", app_name,"--storage-account", storage_account_name,"--os-type", "Linux",], check=True)
Once we've created the Function App, we now want to add the configuration variables to the function app to use in the function. Specifically, we need the OPENAI_API_KEY, the SEARCH_SERVICE_API_KEY, and the EMBEDDINGS_MODEL as these are all used in the function_app.py code.
# Collect the relevant environment variables env_vars = {"OPENAI_API_KEY": openai_api_key,"SEARCH_SERVICE_API_KEY": search_service_api_key,"EMBEDDINGS_MODEL": embeddings_model}# Create the settings argument for the az functionapp create commandsettings_args = []for key, value in env_vars.items(): settings_args.append(f"{key}={value}")subprocess.run(["az", "functionapp", "config", "appsettings", "set","--name", app_name,"--resource-group", resource_group,"--settings", *settings_args], check=True)
We are now ready to publish your function code function_app.py to the Azure Function. This may take up to 10 minutes to deploy. Once this is finished, we now have an API endpoint using an Azure Function on top of Azure AI Search.
Below is a sample OpenAPI spec. When we run the block below, a functional spec should be copied to the clipboard to paste in the GPT Action.
Note that this does not have any authentication by default, but you can set up Azure Functions with OAuth by following the pattern in this cookbook in the Authentication section or looking at the documentation here.
spec =f"""openapi: 3.1.0info: title: Vector Similarity Search API description: API for performing vector similarity search. version: 1.0.0servers: - url: https://{app_name}.azurewebsites.net/api description: Main (production) serverpaths: /vector_similarity_search: post: operationId: vectorSimilaritySearch summary: Perform a vector similarity search. requestBody: required: true content: application/json: schema: type: object properties: search_service_endpoint: type: string description: The endpoint of the search service. index_name: type: string description: The name of the search index. query: type: string description: The search query. k_nearest_neighbors: type: integer description: The number of nearest neighbors to return. search_column: type: string description: The name of the search column. use_hybrid_query: type: boolean description: Whether to use a hybrid query. category: type: string description: category to filter. required: - search_service_endpoint - index_name - query - k_nearest_neighbors - search_column - use_hybrid_query responses: '200': description: A successful response with the search results. content: application/json: schema: type: object properties: results: type: array items: type: object properties: id: type: string description: The identifier of the result item. score: type: number description: The similarity score of the result item. content: type: object description: The content of the result item. '400': description: Bad request due to missing or invalid parameters. '500': description: Internal server error."""pyperclip.copy(spec)print("OpenAPI spec copied to clipboard")print(spec)
Feel free to modify instructions as you see fit. Check out our docs here for some tips on prompt engineering.
instructions =f'''You are an OAI docs assistant. You have an action in your knowledge base where you can make a POST request to search for information. The POST request should always include: {{ "search_service_endpoint": "{search_service_endpoint}", "index_name": {index_name}, "query": "<user_query>", "k_nearest_neighbors": 1, "search_column": "content_vector", "use_hybrid_query": true, "category": "<category>"}}. Only the query and category change based on the user's request. Your goal is to assist users by performing searches using this POST request and providing them with relevant information based on the query.You must only include knowledge you get from your action in your response.The category must be from the following list: {categories}, which you should determine based on the user's query. If you cannot determine, then do not include the category in the POST request.'''pyperclip.copy(instructions)print("GPT Instructions copied to clipboard")print(instructions)